
请教下应用监控eBPF版 node-exporter 带宽流入很大的问题。14:23-15:21 近一个小时,有个节点流量很大,达到近40Mbps我们什么都没有操作麻烦看下华东1 cf9cf04e3336a401fbe5d1d39888afc5e ?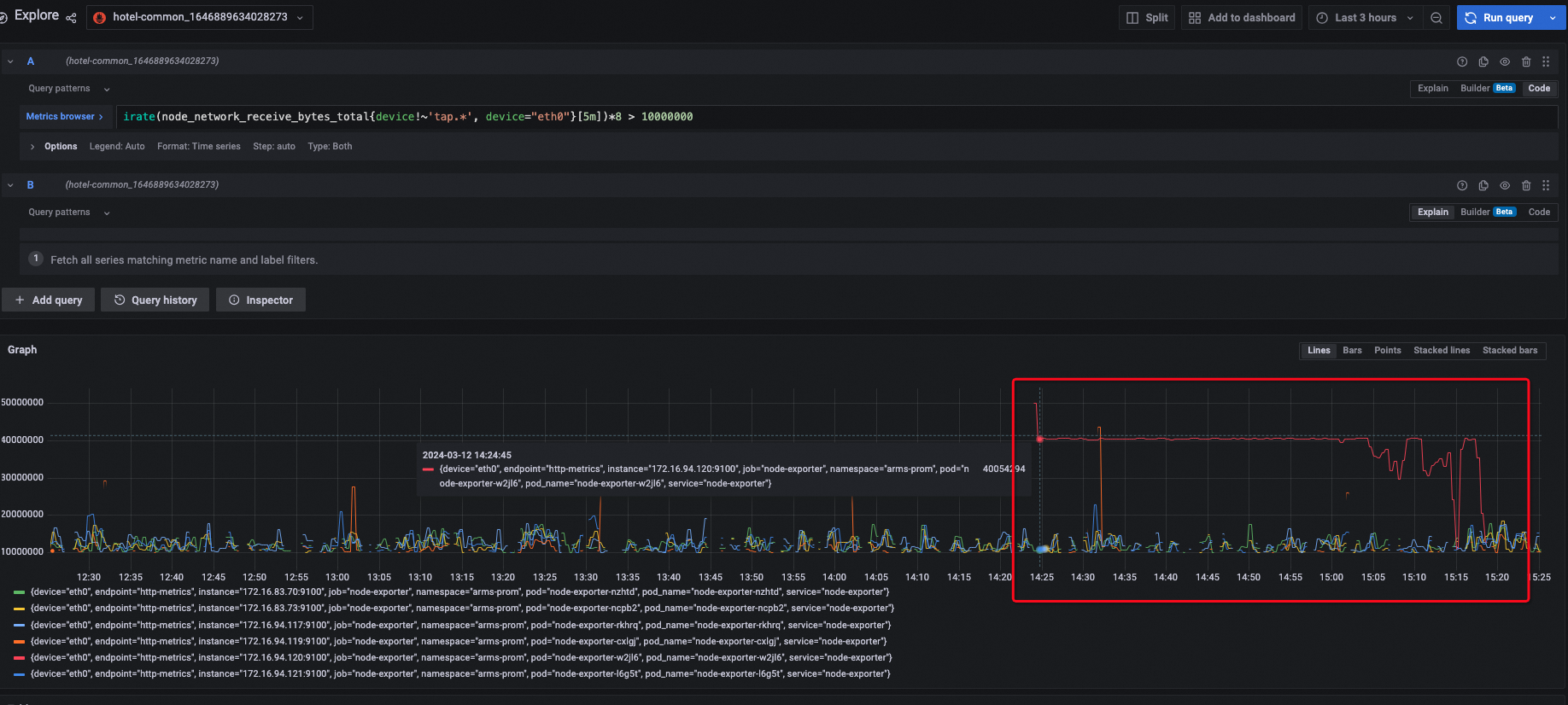
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的信息,应用监控 eBPF 版的 node-exporter 带宽流入异常问题可能与以下因素相关。以下是详细分析和排查步骤:
首先需要确保您的 Kubernetes 集群和节点环境满足应用监控 eBPF 版的运行要求: - Kubernetes版本:需为 v1.20 或更高版本。 - 操作系统:支持 Alibaba Cloud Linux 2/3 或其他内核版本 ≥4.9 的操作系统,并且需通过命令验证是否支持 CONFIG_DEBUG_INFO_BTF=y。 - 资源分配: - 内存建议 ≥4 GB,至少预留 300 MB。 - CPU 建议 ≥2 Core,至少预留 0.3 Core。
如果环境不符合上述要求,可能会导致性能异常或数据采集异常。
应用监控 eBPF 版支持的网络协议包括 HTTP1.1、MySQL、Redis、Kafka 和 DNS。如果您的节点流量主要由这些协议产生,请进一步确认是否存在异常流量来源(如突发请求或恶意访问)。
通过 ARMS 控制台的 全景拓扑图 功能,您可以全局掌握应用服务之间的调用关系及健康状态: 1. 登录 ARMS 控制台,进入 应用监控 eBPF 版 > 应用列表。 2. 选择目标应用,查看 全景拓扑图。 3. 检查是否有异常的服务调用或流量突增现象。
此外,您还可以通过 调用链分析 功能,定位具体接口或服务的流量来源: 1. 在 数据库分析 或 提供服务 页面中,查看对应时间段的请求数、错误数和平均耗时。 2. 如果发现某个接口或数据库的流量异常,可进一步分析其调用链详情。
使用 持续剖析 功能,可以深入分析节点的 CPU 和内存使用情况: 1. 进入目标应用的 应用诊断 > 持续剖析 页面。 2. 选择剖析类型(如 CPU Profiling),查看单个实例的资源消耗情况。 3. 关注 Self 列和 Total 列的数据,定位高耗时或高资源占用的函数。
如果发现某些函数调用异常频繁或耗时过高,可能是导致带宽流入异常的根本原因。
如果您的监控数据已导入 Prometheus 实例,可以通过 Grafana 大盘进一步分析流量趋势: 1. 确认 Prometheus 的 Push Gateway 地址配置正确。 2. 在 Grafana 中查看目标节点的带宽流入趋势图,分析是否存在异常峰值。 3. 对比其他节点的流量数据,判断是否为单节点问题。
如果以上步骤无法定位问题,建议联系应用监控 eBPF 版答疑钉钉群(群号:35568145)获取帮助。在反馈问题时,请提供以下信息: - 异常时间段(如 14:23-15:21)。 - 节点 ID(如华东1 cf9cf04e3336a401fbe5d1d39888afc5e)。 - 相关日志或截图(如全景拓扑图、调用链分析结果)。
通过以上步骤,您可以逐步排查并定位带宽流入异常的原因。如果仍有疑问,请随时联系技术支持团队。
云原生可观测基于Prometheus、Grafana 、OpenTelemetry 等核心产品, 形成指标、链路存储分析、异构数据源集成的数据层, 通过标准PromQL和SQL提供大盘展示、告警与探索能力。
