
Flink CDC 里这是什么问题?TaskManager内存这样配置的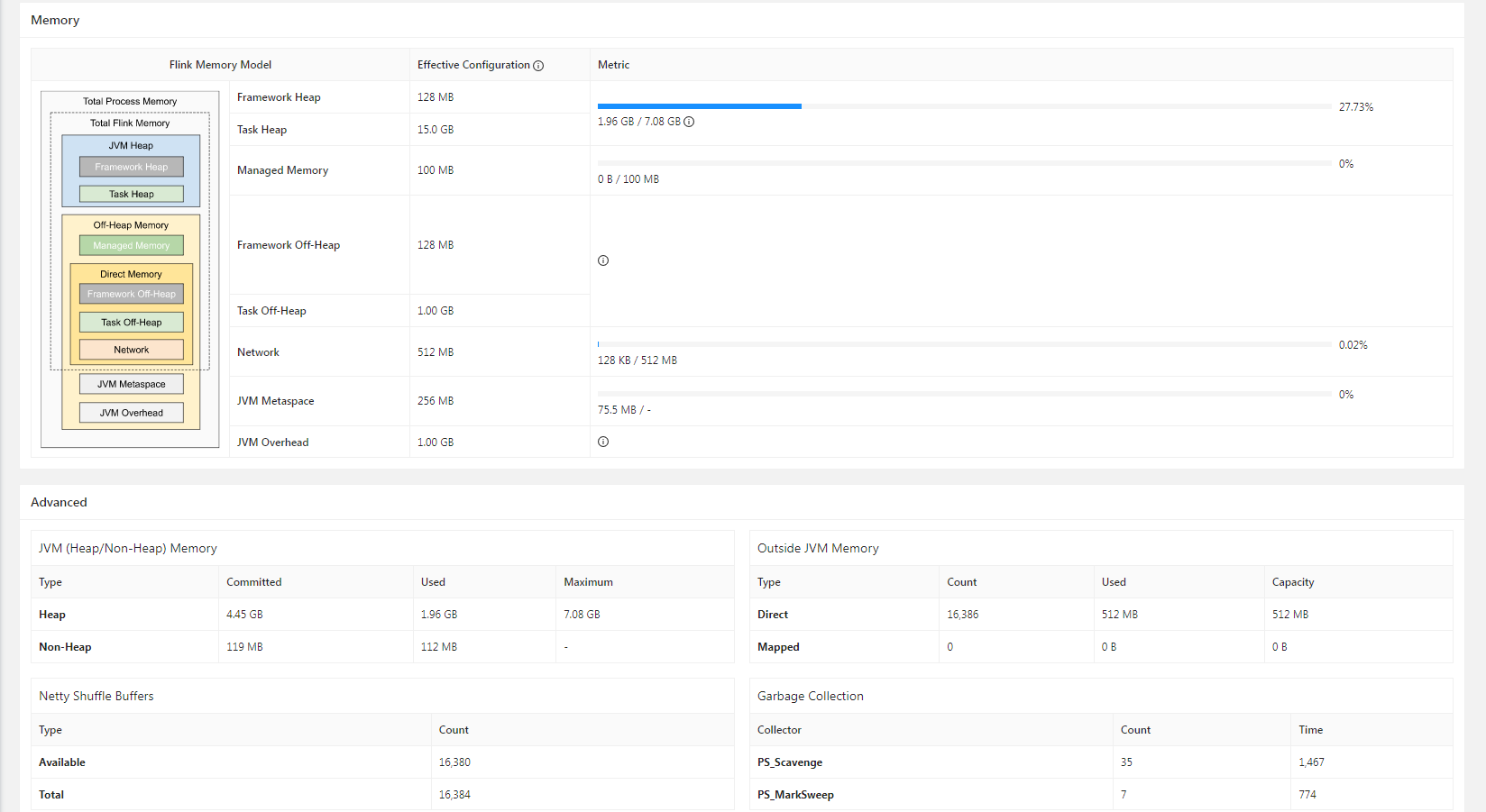 [flink-akka.actor.default-dispatcher-60] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Sink gimi_ods.log_xxt_api (1/1) (bf5fbf8c494231799fc38e85fbd084fb) switched from RUNNING to FAILED on 6ab16bb7-4aa2-4cb9-84ca-55e3c0afba00 @ genuine.microsoft.com (dataPort=-1).
[flink-akka.actor.default-dispatcher-60] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Sink gimi_ods.log_xxt_api (1/1) (bf5fbf8c494231799fc38e85fbd084fb) switched from RUNNING to FAILED on 6ab16bb7-4aa2-4cb9-84ca-55e3c0afba00 @ genuine.microsoft.com (dataPort=-1).
java.nio.BufferOverflowException
at java.nio.HeapByteBuffer.put(HeapByteBuffer.java:192)
at java.nio.ByteBuffer.put(ByteBuffer.java:859)
at com.selectdb.flink.sink.writer.RecordBuffer.insert(RecordBuffer.java:39)
at com.selectdb.flink.sink.writer.SelectdbStageLoad.writeRecord(SelectdbStageLoad.java:126)
at com.selectdb.flink.sink.writer.SelectdbWriter.write(SelectdbWriter.java:81)
at org.apache.flink.streaming.runtime.operators.sink.SinkOperator.processElement(SinkOperator.java:163)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:233)
at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134)
at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105)
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:495)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:806)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:758)
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
at java.lang.Thread.run(Thread.java:750)
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的错误日志,java.nio.BufferOverflowException 是由于 HeapByteBuffer 的容量不足导致的。这通常发生在 Flink CDC 作业中,当数据写入 Sink 时,Sink 的缓冲区(Buffer)无法容纳当前的数据量,从而引发溢出异常。
具体来看,错误堆栈显示问题出现在 com.selectdb.flink.sink.writer.RecordBuffer.insert 方法中,表明在将记录写入 SelectDB Sink 时,缓冲区的大小不足以容纳单条记录或批量记录。
taskmanager.memory.process.size: 4g # 根据实际需求调整
taskmanager.memory.task.heap.size: 2g # 堆内存大小
taskmanager.memory.managed.fraction: 0.5 # 默认值为 0.4,可适当提高
write-buffer-size 参数的值(默认值为 256 MB):
'write-buffer-size' = '512MB' # 根据实际数据量调整
'orc.write.batch-size' = '512' # 默认值为 1024,可适当减小
'file.format' = 'avro',
'metadata.stats-mode' = 'none'
parallelism.default: 4 # 根据实际需求调整
execution.batch.adaptive.auto-parallelism.enabled: true
检查 TaskManager 内存配置:
taskmanager.memory.process.size 和 taskmanager.memory.task.heap.size 是否足够。调整 Sink 缓冲区大小:
write-buffer-size 参数,确保其能够容纳较大的数据记录。优化数据写入参数:
orc.write.batch-size 或切换到 AVRO 格式。增加并发度:
监控磁盘空间:
通过以上步骤,您可以有效解决 BufferOverflowException 问题,并优化 Flink CDC 作业的性能。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

