
flink cdc同步一个oracle表,数据量大概800万,检查点失败,有朋友能给点排查思路么?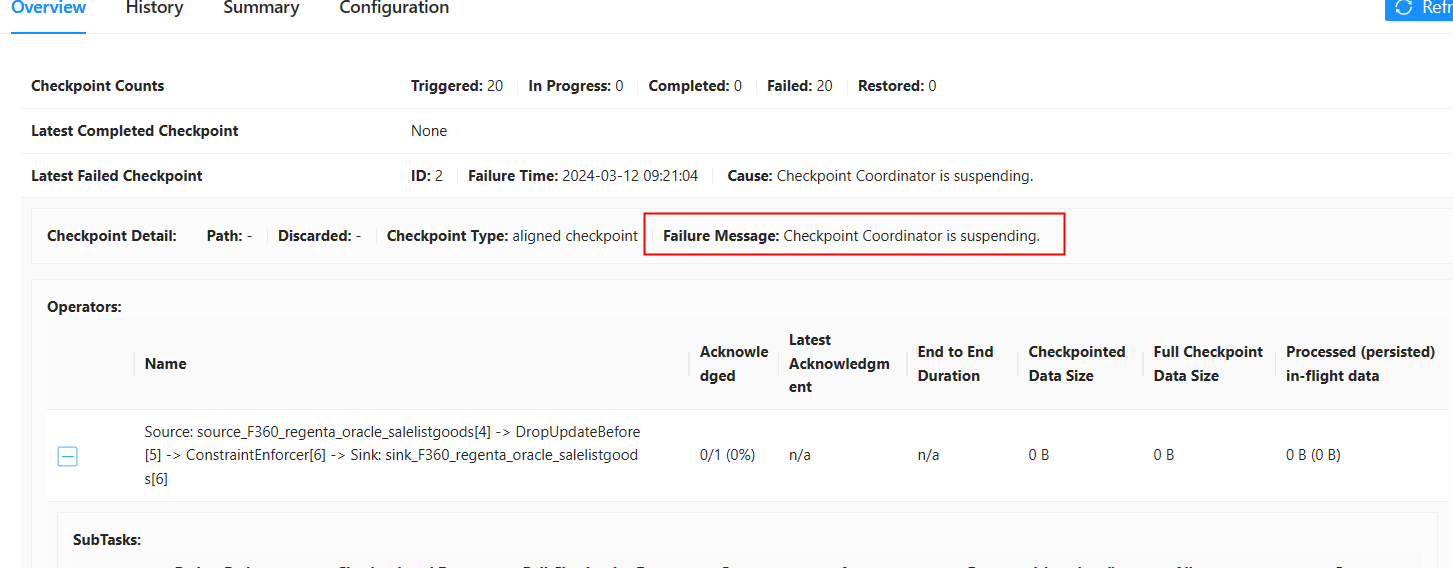
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC同步Oracle表时,如果数据量较大(如800万条记录)且检查点失败,可能是由于状态规模过大、资源不足或配置不当导致的。以下是详细的排查思路和优化建议:
检查点失败通常与以下因素相关: - 状态规模过大:Flink需要将状态写入检查点,如果状态过大可能导致超时或失败。 - 网络带宽不足:检查点数据需要通过网络传输,带宽不足会导致失败。 - 磁盘IO瓶颈:检查点数据写入磁盘时,磁盘性能不足可能导致失败。 - 反压问题:作业处理速度跟不上数据输入速度,导致状态持续增长。
Checkpoint expired before completing:检查点超时。Not enough memory to buffer state:内存不足。TimeoutException:网络或磁盘IO超时。execution.checkpointing.timeout),例如设置为10分钟或更长。SET 'table.exec.state.ttl' = '1h'; -- 设置状态TTL为1小时
'scan.startup.mode' = 'latest-offset'
execution.checkpointing.interval),例如设置为5分钟。SET 'state.backend.incremental' = 'true';
SET 'state.backend.local-recovery' = 'true';
jdbcWriteBatchSize)。WITH ('jdbcWriteBatchSize' = '1024')
CREATE TABLE IF NOT EXISTS target_table
AS TABLE source_catalog.database_name.table_name;
通过以上排查和优化措施,可以有效解决Flink CDC同步Oracle表时检查点失败的问题。重点在于减少状态规模、优化资源配置和提升Sink写入性能。如果问题仍然存在,建议结合具体日志信息进一步分析。
希望这些建议能帮助您解决问题!您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

