
Flink CDC里这个是什么原因?我看包也没冲突的,0.14.1的hudi作为flink cdc的sink。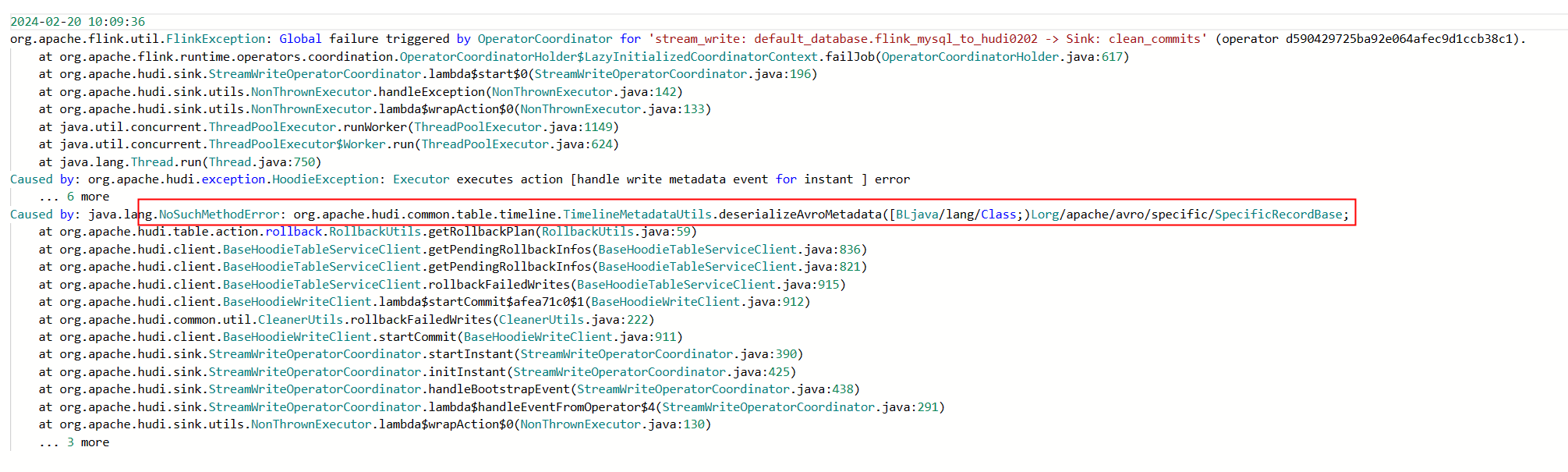 类也能引进来
类也能引进来 也没冲突
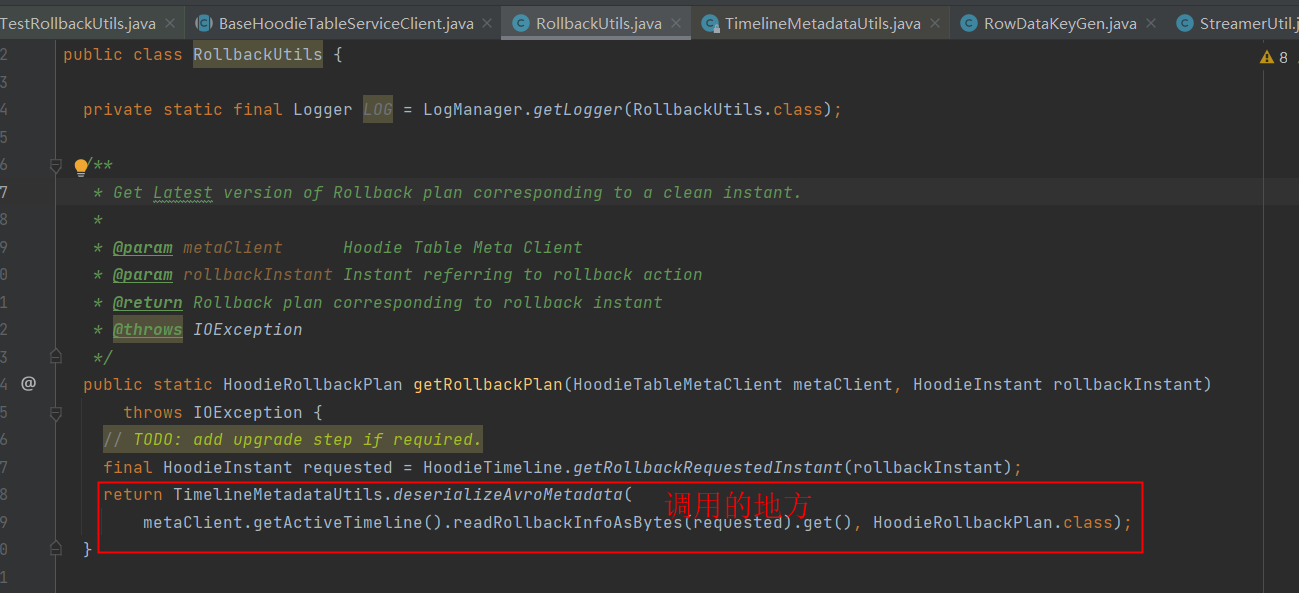
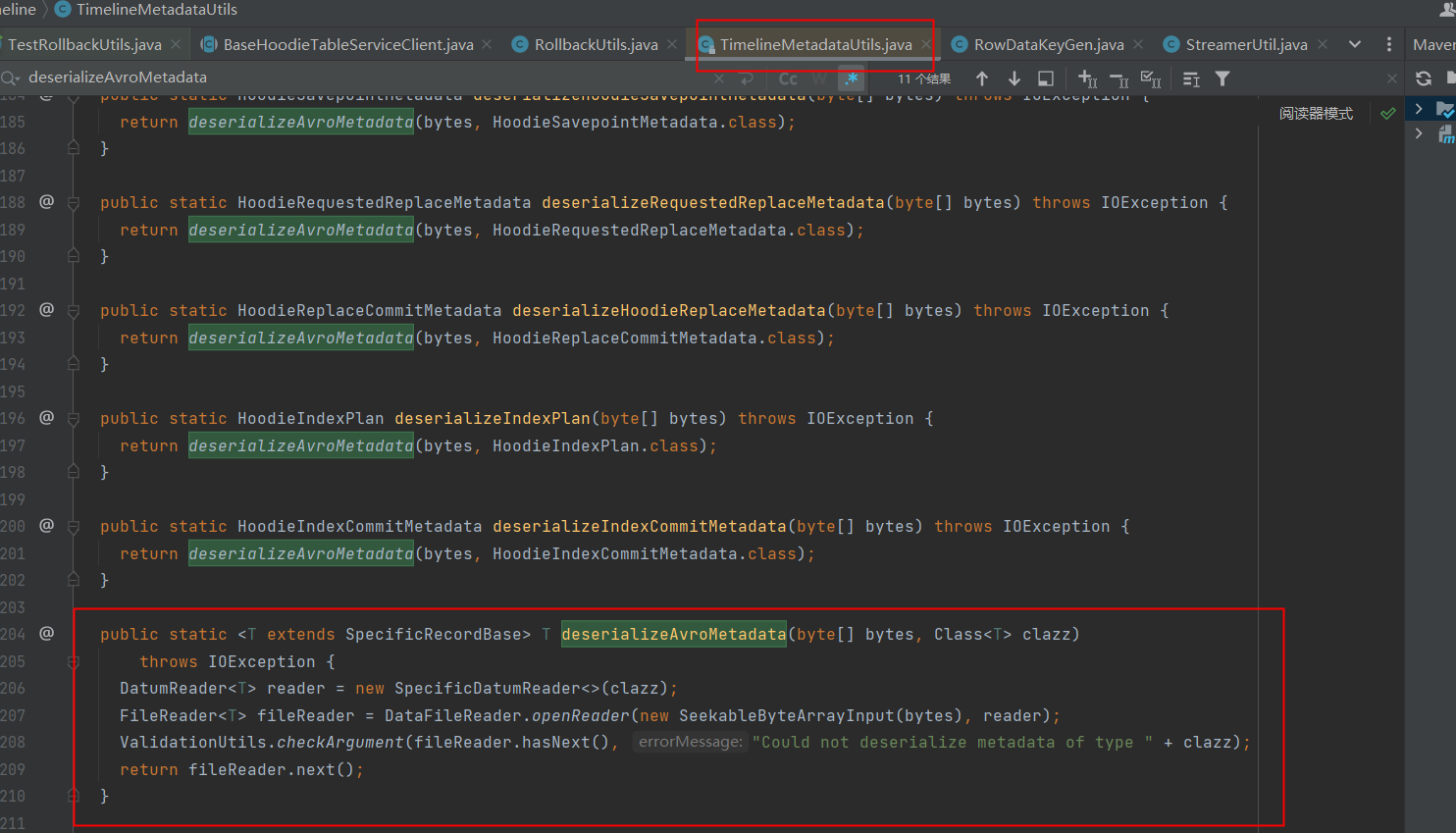
也没冲突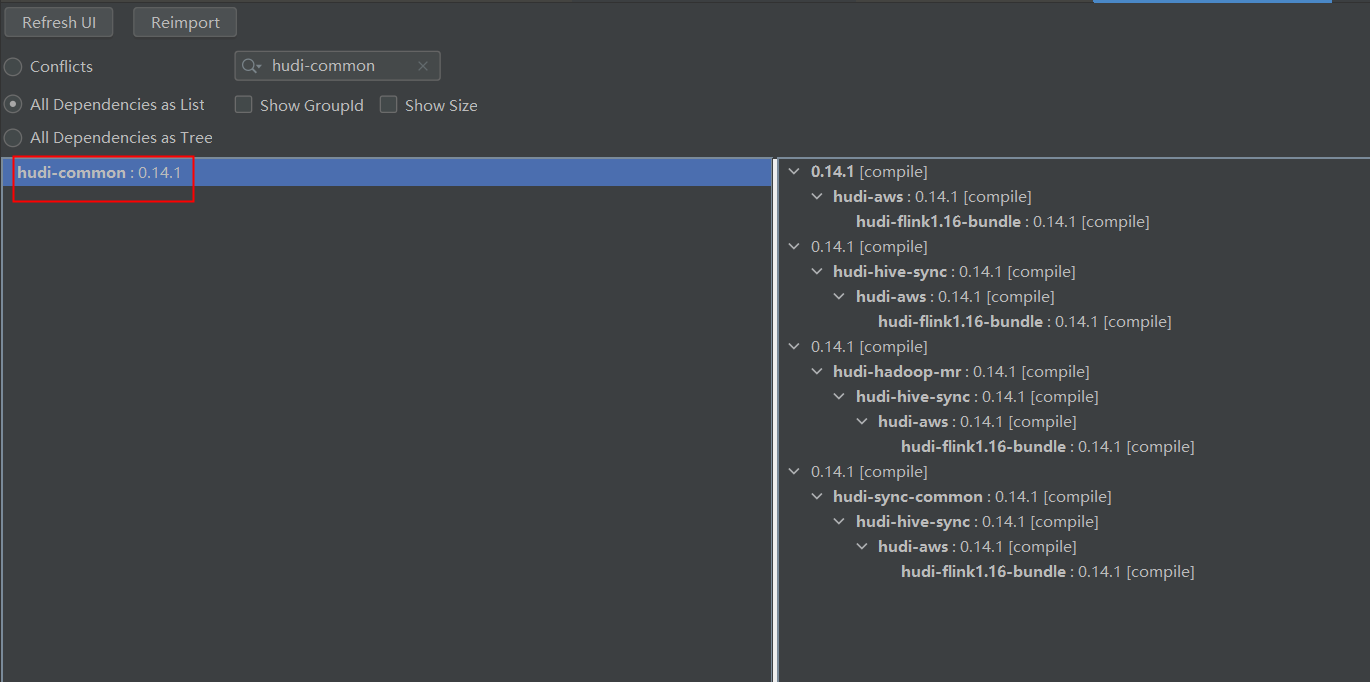
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC 使用 Hudi 作为 Sink 时出现异常,尽管您确认包没有冲突且类能够正常引入。以下是可能的原因分析及解决方案:
Hudi 和 Flink 的版本可能存在不兼容的情况。虽然您提到使用的是 Hudi 0.14.1 和 Flink CDC,但需要确保两者的版本在功能和依赖上是完全兼容的。
尽管您提到类能够正常引入且没有冲突,但在分布式环境中,类加载顺序可能导致隐式冲突。
classloader.parent-first-patterns.additional: org.apache.hudi
provided,避免重复引入依赖:<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-bundle</artifactId>
<version>0.14.1</version>
<scope>provided</scope>
</dependency>
Hudi 的某些配置可能未正确设置,导致与 Flink CDC 的集成失败。
BUCKET 索引以减少存储开销:index.type=BUCKET
hoodie.bucket.index.num.buckets=8
hoodie.base.path=oss://your-bucket/path
Flink CDC 的数据流可能包含更新或删除操作,而 Hudi 的写入逻辑未正确处理这些操作。
UPDATE_BEFORE 和 UPDATE_AFTER),可能需要额外配置。INSERT INTO 语法简化开发代码:INSERT INTO hudi_table SELECT * FROM cdc_source;
作业运行过程中可能出现资源不足的情况,导致异常。
clustering.plan.strategy.partition.regex.pattern=.*
clustering.plan.strategy.cluster.begin.partition=2023-01-01
clustering.plan.strategy.cluster.end.partition=2023-12-31
如果上述方法仍无法解决问题,建议通过日志进一步排查。
以上分析涵盖了版本兼容性、类加载冲突、Hudi 配置、数据流处理逻辑以及资源限制等多个方面。建议您按照以下步骤逐一排查: 1. 确认 Hudi 和 Flink 的版本兼容性。 2. 检查类加载配置,避免隐式冲突。 3. 核对 Hudi 的索引类型和文件系统配置。 4. 确保数据流处理逻辑与 Hudi 的写入模式匹配。 5. 增加资源配额,优化小文件合并策略。
如果问题仍未解决,请提供更详细的错误日志以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

