
1
条回答
 写回答
写回答
-

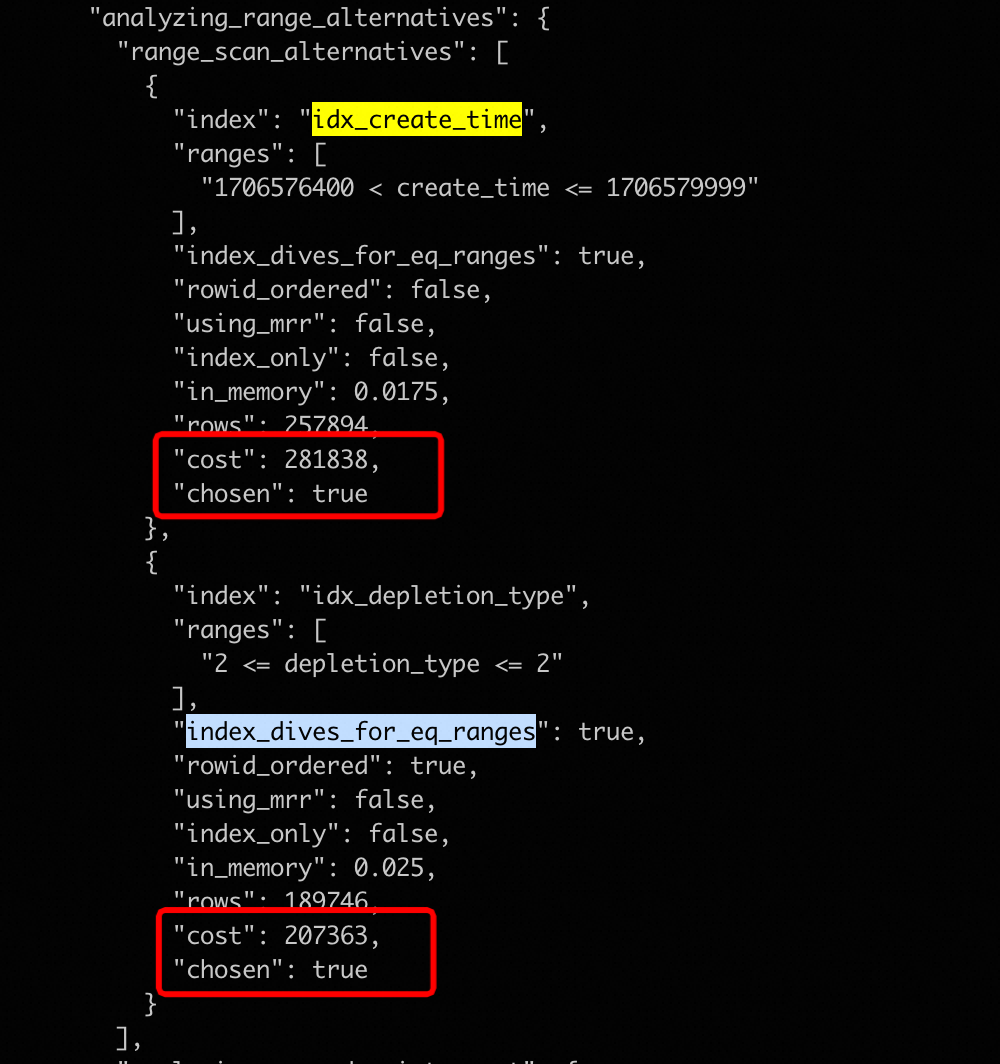
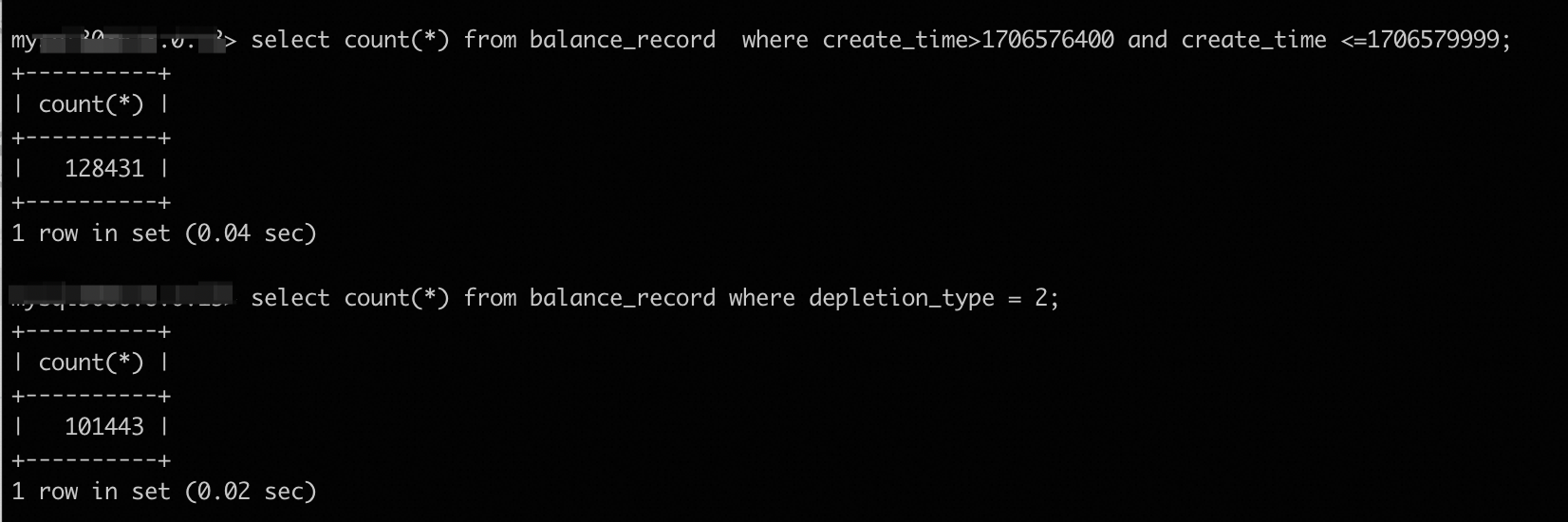
两句中间少个分号,set前加个分号吧,基于cost选择的"index": "idx_depletion_type"基于当前query,这两个索引idx_depletion_type, idx_create_time需要扫描的数据量如下优化器选择的索引没有问题的;不过两个索引的代价相差不是很大, 如果变动时间范围,对应数据量不一样,代价不一样,也可能会选择另外一个索引?
,此回答整理自钉群“PolarDB 专家面对面 - 慢SQL索引选择优化器新特性”2024-02-08 14:42:20赞同 展开评论 打赏
问答分类:
相关产品:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答

阿里云关系型数据库主要有以下几种:RDS MySQL版、RDS PostgreSQL 版、RDS SQL Server 版、PolarDB MySQL版、PolarDB PostgreSQL 版、PolarDB分布式版 。
热门讨论
热门文章
PolarDB可以在本地部署吗 ?
1297
RDS,DRDS,REDIS,ADS,ODPS之间的联系和区别是什么?
8348
有了RDS,为什么要有DRDS,DRDS的功能是什么?
386
PolarDB这个数据库免费试用多久? 后续怎么收费?
468
Mysql中 flush priviledges是什么意思
206
逻辑存储和物理存储各代表什么?区别是什么?
596
PolarDB分区表中,多少条记录适合创建一个分区?
379
PolarDB 和 PolarDB-X 应该选哪个比较好?
353
polarDB和RDS的mysql具体区别在哪里呢?
345
polardb 大表9亿数据,创建一个索引用了4小时,有没有方法可以加快创建索引的速度?
169
展开全部
Linux 性能诊断 perf使用指南
48061
PostgreSQL 如何潇洒的处理每天上百TB的数据增量
38445
Jedis常见异常汇总
38961
PostgreSQL 百亿数据 秒级响应 正则及模糊查询
28918
PostgreSQL 金融行业高可用和容灾解决方案
18555
Greenplum 通过gpfdist + EXTERNAL TABLE 并行导入数据
16875
PostgreSQL 全文检索加速 快到没有朋友 - RUM索引接口(潘多拉魔盒)
18383
让人敬佩的白发程序员——MySQL/MariaDB之父Monty阿里交流会
14697
PostgreSQL 全表 全字段 模糊查询的毫秒级高效实现 - 搜索引擎也颤抖了
14650
PostgreSQL 十亿级模糊查询最佳实践
13942
展开全部


相关电子书
更多

