
实时计算 Flink版公司要求用docker部署flink集群 这种情况 最少需要几台服务器呀?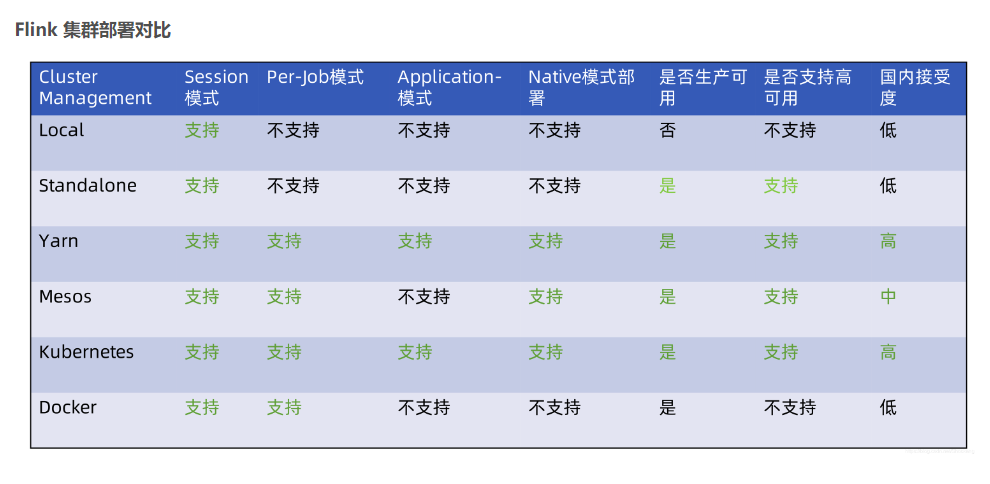
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Docker部署Apache Flink集群时,理论上创建一个最小规模的集群至少需要两台服务器(或两个Docker容器),分别运行JobManager和TaskManager。
JobManager(作业管理器):负责整个Flink作业的调度与协调,包括任务分配给TaskManager等管理工作。在一个集群中,通常只需要一个JobManager实例即可。
TaskManager(任务管理器):实际执行计算任务的worker节点,每个TaskManager包含多个slot,用于执行并行任务。为了实现分布式计算和高可用性,至少需要一个TaskManager实例。
然而,在单机环境下,也可以在同一台服务器上运行Docker,并在不同的Docker容器中分别启动JobManager和TaskManager来模拟集群环境,但这仅适用于开发和测试场景,并不能提供真正的容错性和高可用性。
对于生产环境,推荐的做法是至少有两台独立的服务器(或容器),其中一个运行JobManager,另一个运行TaskManager。如果考虑高可用性,则JobManager通常会部署成高可用模式,这意味着还需要额外的备用JobManager节点,以防主JobManager故障时能自动接管作业管理。
因此,简单生产环境下的最小集群可能是:
而对于高可用集群,至少需要:
部署Flink集群至少需要3台服务器。
在实时计算领域,Apache Flink是一个广泛使用的框架,它支持事件驱动型的数据处理,并能提供高吞吐量和低延迟的计算。当公司要求使用Docker来部署Flink集群时,这通常涉及到将Flink的各个组件容器化,然后运行在Docker环境中。
为了确保集群的高可用性和容错性,建议至少使用3台服务器。这样的配置允许你运行至少2个任务管理器(TaskManager)的实例和一个作业管理器(JobManager)的实例。这种配置可以保证即使失去一台服务器,集群仍然能够继续运行而不会中断服务。具体来说:
此外,如果集群规模较大或者作业较为复杂,可能需要更多的服务器来保证集群的性能和稳定性。在实际部署时,还需要考虑网络配置、资源分配、数据持久化等因素。
需要注意的是,上述建议是基于一般性的假设,实际部署时应根据具体的业务需求和资源情况进行调整。
别用docker,用yarn,和hadoop,hfds都是无缝支持的,这是一套,兼容性最好,推荐的还是k8s,虽然虚拟化的还是docker的镜像 ,此回答整理自钉群“【③群】Apache Flink China社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


