
请问大数据计算MaxCompute已上传zip格式资源,想调用它但一直报错,请问是用法不对吗?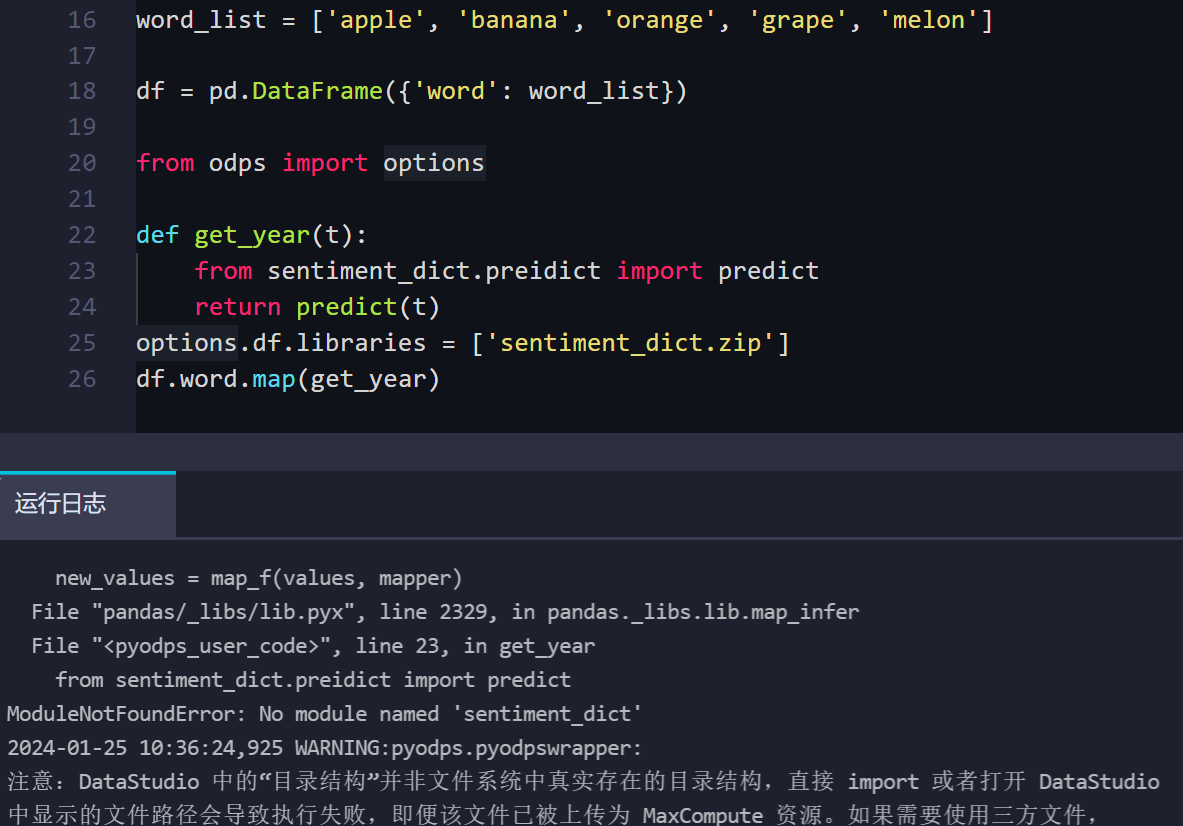
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute中调用已上传的zip格式资源时,如果一直报错,可能是由于以下几个原因导致的。以下是详细的排查步骤和解决方法:
zip格式的资源需要以ARCHIVE类型上传。如果资源类型不正确(例如被误上传为FILE类型),会导致调用失败。desc resource <resource_name>;
如果资源类型不是ARCHIVE,请重新上传资源:
add archive <file_name>;
xxx.zip,但实际文件是xxx.tar.gz),解压时会失败。add archive xxx.zip;
desc function <function_name>;
如果资源列表中缺少所需的zip资源,请重新注册函数:
create function <function_name> as '<package_to_class>' using '<resource_list>';
其中,<resource_list>应包含所有依赖的资源。
zip资源时通常使用get_cache_archive方法。如果引用方式不正确,也会导致报错。解决方法: 确保代码中正确引用资源。例如:
from odps.distcache import get_cache_archive
def my_udf():
archive_path = get_cache_archive('xxx.zip')
# 解压并使用资源
zip资源中的包依赖于Python 3,可能会导致导入失败。set odps.sql.python.version=cp37;
zip资源中包含第三方库,需要在代码中显式将包路径加入sys.path,否则可能导致导入失败。解决方法: 修改代码,确保路径正确。例如:
import sys
sys.path.insert(0, 'work/xxx.zip')
import your_module
list resources;
如果资源不存在,请重新上传:
add archive <file_name>;
zip资源,必须确保其兼容Linux环境。如果资源是在Windows或Mac下生成的,可能无法在MaxCompute中使用。python setup.py bdist_wheel
然后将生成的whl文件重命名为zip后缀并上传。
set odps.isolation.session.enable=true;
通过以上步骤逐一排查,应该可以解决调用zip资源时的报错问题。如果问题仍未解决,请提供具体的错误信息以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

