
DataWorks指定了split.size 为什么input 的 records还会如此不均等呢?
DataWorks指定了split.size 为什么input 的 records 还会如此不均等呢?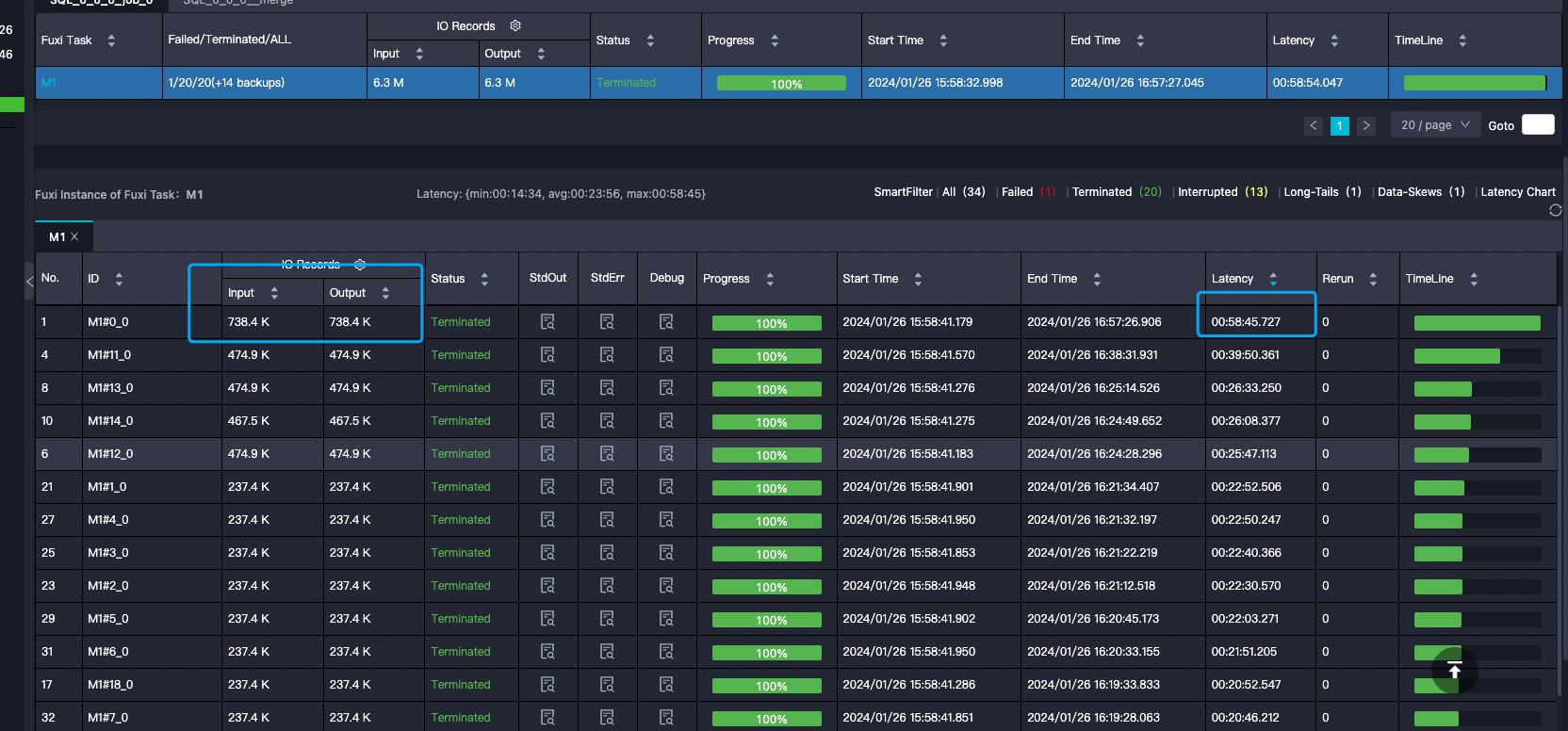
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
条回答
写回答
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
在DataWorks中,尽管可以通过设置
split_size来控制Map任务的数据输入量,但在某些情况下,您可能会发现输入的records分布并不均匀。这可能是由于以下原因造成的:- 数据本身分布不均:如果原始数据集本身就存在分布不均的情况,即使设置了
split_size,也无法完全保证每个split的数据量相等。 - 数据处理逻辑:在数据处理过程中,如果使用了如
split或split_part等函数对字符串进行拆分,这可能会影响records的最终分布。因为拆分操作可能会导致某些records的数据量增加。 - 并行度和资源分配:在分布式计算中,并行度和资源分配也会影响数据处理的结果。如果资源分配不均或者并行度设置不合理,也可能导致records处理不均等。
- 系统调度和执行:系统的调度和执行策略也可能影响数据的分布。例如,不同的任务可能会被分配到不同的节点上执行,节点的性能差异或者网络延迟等因素都可能导致records处理的不均衡。
split_size参数的影响范围:虽然split_size可以控制单个Map任务的最大数据输入量,但它并不能直接决定records的分布情况。它主要是用来控制每个Map任务处理的数据量,而不是确保数据在所有Map任务中均匀分布。
为了改善records的分布情况,您可以尝试以下方法:
- 优化数据预处理:在数据处理之前,对数据进行预处理,尽量使得数据分布更加均匀。
- 调整并行度:根据数据量和集群资源情况,合理设置并行度,以便更有效地利用资源。
- 使用更高级的数据划分策略:如果可能,可以考虑使用更高级的数据划分策略,如基于数据内容的哈希划分,以实现更均匀的数据分布。
- 监控和调整:在数据处理过程中,监控各个任务的执行情况,根据实际情况进行调整。
综上所述,虽然
split_size是一个重要的参数,但它并不是唯一影响records分布的因素。在实际操作中,需要综合考虑多种因素,通过不断的测试和调整来优化数据处理流程。2024-01-28 22:12:33赞同 展开评论 - 数据本身分布不均:如果原始数据集本身就存在分布不均的情况,即使设置了

问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
大数据开发治理DataWorks
>
问答
相关问答

DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理