
Flink CDC全量和增量同步数据如何保证数据的一致性,不丢失和不重复读取?全量和增量是如何衔接的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Apache Flink 的 Change Data Capture (CDC) 功能主要用于实时捕获数据库中的变更记录,并将其转换为事件流以供下游处理。为了保证全量和增量数据同步时数据的一致性、不丢失和不重复读取,Flink CDC 采用了以下策略:
事务边界:Flink CDC 通常依赖于数据库的日志(如 MySQL 的 binlog 或 PostgreSQL 的 wal 日志)来捕获事务级别的更改。这意味着它能识别事务的开始和结束,从而确保在处理变更事件时保持事务的一致性。
精确一次处理语义:Flink 作为流处理引擎本身支持精确一次(exactly-once)的状态一致性保证。通过 checkpoint 和两阶段提交机制,Flink 能够在故障恢复时准确地回滚或重放事件,从而避免数据丢失和重复处理。
幂等消费:对于消息中间件(如 Kafka)而言,Flink 通过消费组的幂等性保证即使在故障重启后也能正确处理消息,防止因重复消费导致的数据不一致。
全量数据同步:
增量数据同步:
合并处理:
通过这些机制,Flink CDC 实现了全量数据导入和增量数据实时追加之间的平滑过渡,有效保证了数据的完整性与一致性。
进行全量同步阶段时,Flink CDC 通常依赖数据库的快照机制(如 MySQL 的 binlog 或 PostgreSQL 的逻辑复制 slot)获取某个时间点或事务边界的所有数据状态。
Flink CDC(Change Data Capture)是一种用于捕获数据库中数据变更的技术。在Flink CDC中,全量和增量同步数据的一致性、不丢失和不重复读取可以通过以下方式保证:
事务支持:Flink CDC通过与数据库的事务机制结合使用,确保在同步过程中数据的一致性。当进行全量或增量同步时,Flink会将操作封装为一个事务,以确保数据的完整性和一致性。
幂等性处理:Flink CDC会对每个事件进行处理,并确保每个事件的处理是幂等的。这意味着无论事件被处理多少次,结果都是相同的。这样可以避免重复读取数据的问题。
基于时间戳的检查点:Flink CDC使用基于时间戳的检查点机制来保证数据的不丢失。当进行全量或增量同步时,Flink会记录当前处理的位置,并在发生故障时从最近的检查点恢复。这样可以确保不会重复读取已经处理过的数据。
数据去重:Flink CDC提供了内置的数据去重功能,可以自动识别和删除重复的数据。这样可以避免在同步过程中出现重复读取的问题。
全量和增量的衔接可以通过以下方式实现:
全量同步:首先进行一次全量同步,将所有变更的数据都同步到目标系统。这样可以确保目标系统中有完整的数据副本。
增量同步:然后进行增量同步,只同步自上次全量同步以来发生的变更。这样可以保持目标系统中数据的实时性,同时减少数据传输和处理的开销。
通过以上方式,Flink CDC可以保证全量和增量同步数据的一致性、不丢失和不重复读取,并且能够无缝衔接全量和增量同步过程。
Flink CDC(Change Data Capture)是一种用于捕获数据库中数据变更的技术,它可以实现对数据库全量和增量数据的同步。在全量和增量同步过程中,Flink CDC 通过以下方式保证数据的一致性:
Apache Flink CDC(Change Data Capture)通过一系列设计和机制来保证数据的一致性、不丢失和不重复读取。以下是Flink CDC在全量和增量同步数据时保证数据完整性和一致性的关键方法:
Snapshotting: Flink CDC通常采用初始的全量数据导入,通过获取数据库某一时刻的快照来保证全量数据的一致性。例如,MySQL Binlog CDC可以通过mysqldump工具或者其他方式获取一个时间点的数据快照。
一致性保证: 在开始全量导入之前,可以设置数据库事务隔离级别或者采用特定的锁机制,确保在抓取数据快照期间不会有新的事务提交,从而避免数据不一致。
Binlog/Transaction Log Tailer: 一旦全量同步完成后,Flink CDC开始监听数据库的二进制日志(如MySQL的binlog、PostgreSQL的WAL)或者变更日志,跟踪所有的事务更改。这种方式能够实时捕获到数据库的所有增删改操作。
Exactly-once语义: Flink自身支持 Exactly-once 的状态一致性保证,这意味着即使在故障恢复之后,每个变更事件只会被处理一次,不会丢失也不会重复。
Watermark & Checkpoint: Flink通过 watermarking 和 checkpoint 机制来处理乱序事件和容错。Watermarks帮助系统定义事件时间窗口,而checkpoint用于定期保存状态并在失败时恢复状态,确保即使在系统故障后也能继续从上次中断的地方准确地继续处理增量数据。
幂等性写入: 输出端(sink)的设计也需要具备幂等性,这样当同一个事件因故障恢复等原因被重新投递时,不会导致目标系统中数据的重复。
全量和增量的衔接:

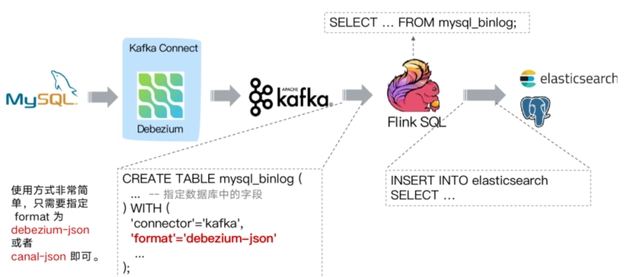
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


