
云数据仓库ADB中,数据量大概 5000 万行,超过一定时间就断开了,大概有一小时左右,是否与参数对 select 取数造成以下错误有关系?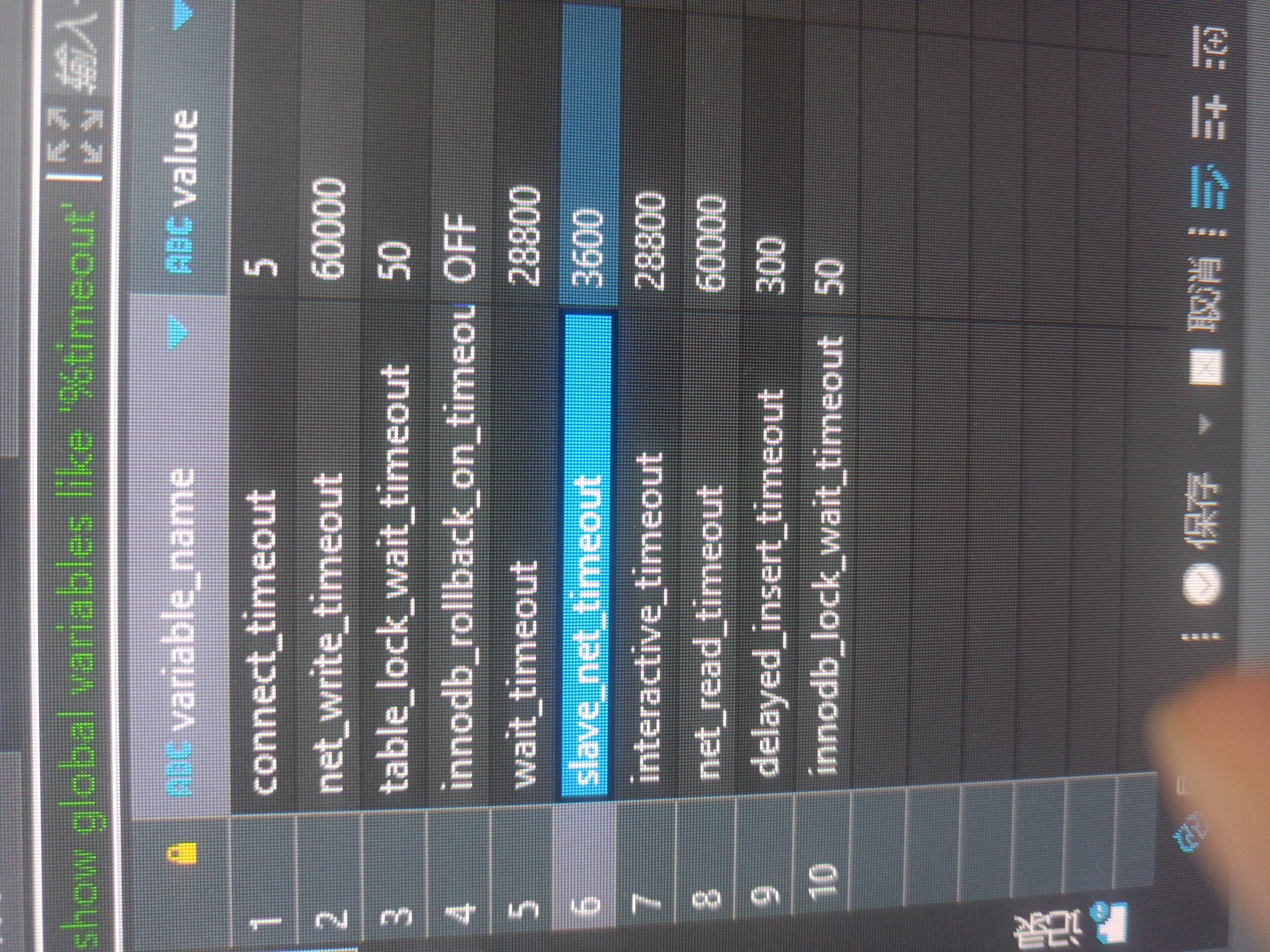
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在云数据仓库AnalyticDB MySQL版中,有几个参数可能影响SELECT查询的执行及其稳定性,尤其是在处理大量数据时。
查询超时时间:查询超时时间(QUERY_TIMEOUT)是控制单个查询允许执行的最长时间。如果查询耗时超过这个时间限制,查询将被终止并返回错误。默认的超时时间为1800000.00毫秒,约30分钟。如果您的查询需要更长的时间来执行,您可以设置这个参数来延长查询超时时间。
资源组:资源组(Resource Groups)用于资源隔离,确保SQL作业之间的相互不影响。如果您的查询作业没有分配到足够的计算资源,它可能会因为资源竞争而断开。确保您的查询作业在合适的资源组中运行,并且资源组有足够的ACU(按需计算单元)。
连接超时时间:连接超时时间是指建立数据库连接时允许等待的时间,超过这个时间则连接建立失败。如果连接超时设置得过短,查询可能在从数据库获取数据时因为无法及时建立连接而失败。
主机的网络稳定性:如果主机的网络连接不稳定,也可能导致查询中断。确保您的网络连接稳定,并且数据库实例对外部请求没有做过多的网络安全限制。
数据库配置:数据库的配置参数,如innodb_buffer_pool_size、query_cache_size等,也会影响数据库的性能和稳定性。对于大量数据的查询,可能需要调整这些参数来优化性能。
针对您提到的问题,建议首先检查QUERY_TIMEOUT设置,如果数据量较大且查询复杂,可适当调整此参数以延长查询时间。其次,确保资源组中有足够的资源供查询作业使用。此外,考虑网络稳定性和数据库配置也是必要的。如果需要进一步的帮助,建议联系阿里云技术支持获取更专业的诊断。
对于AnalyticDB for MySQL(简称ADB)的select取数操作,可能会受到以下参数的影响:
超时时间:如果查询操作超过了设置的超时时间,那么查询就会被中断。您可以通过修改wait_timeout和interactive_timeout参数来调整超时时间。
最大连接数:如果同时连接到数据库的客户端数量超过了最大连接数,那么新的连接请求就会被拒绝。您可以通过修改max_connections参数来调整最大连接数。
查询缓存:如果查询结果被缓存了,那么在缓存过期之前,相同的查询就不会再次执行。这可能会导致查询结果不准确或者延迟。您可以通过修改query_cache_type和query_cache_size参数来调整查询缓存。
查询优化器:查询优化器会根据表结构和索引等信息来选择最优的查询计划。如果查询优化器选择了低效的查询计划,那么查询性能就会受到影响。您可以通过修改optimizer_switch参数来调整查询优化器的行为。
数据分片:如果数据被分片存储,那么查询操作可能需要跨越多个分片进行。这会增加查询的复杂性和延迟。您可以通过修改sharding_num和sharding_key参数来调整数据分片的策略。
以上这些参数都可能影响到select取数操作的性能和稳定性。如果您遇到了问题,建议您先检查这些参数的配置是否正确,并根据实际情况进行调整。
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。


