
DataWorks任务是否可以按小时设置自依赖?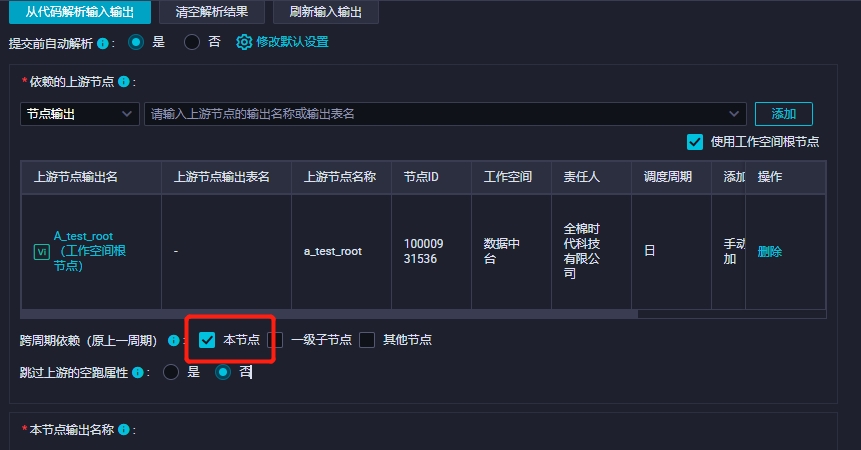
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的,DataWorks任务可以按小时设置自依赖。通过配置小时任务的自依赖,可以实现当前周期实例依赖上一周期实例的执行结果,从而确保任务按照预期顺序运行。
进入调度配置页面
在数据开发节点的编辑页面中,单击右侧导航栏的调度配置。
设置依赖上一周期
在时间属性区域,找到依赖上一周期选项,选择本节点。这表示当前小时任务的每个周期实例将依赖其上一个周期实例的成功执行。
保存并提交配置
完成配置后,保存并提交任务,确保调度系统能够识别新的依赖关系。
对当前节点的影响
配置自依赖后,小时任务的每个周期实例将依赖上一周期实例的成功执行。例如,假设小时任务从0点开始每小时调度一次,那么1点的实例需要等待0点的实例成功执行后才会运行。
对下游节点的影响
如果下游任务(如天任务)依赖该小时任务,则下游任务会间接依赖小时任务的多个周期实例。例如,当天任务依赖小时任务时,若小时任务设置了自依赖,天任务实际上会依赖小时任务的所有上游周期实例。
自依赖的默认行为
配置自依赖后,今天第一个小时实例将依赖昨天最后一个小时实例。因此,在跨天的任务调度中需特别注意这种依赖关系。
依赖线的表现形式
在运维中心查看依赖关系时,自依赖会以虚线的形式展示,而同周期依赖则以实线展示。
通过以上配置和注意事项,您可以成功为小时任务设置自依赖,并确保任务调度符合业务需求。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

