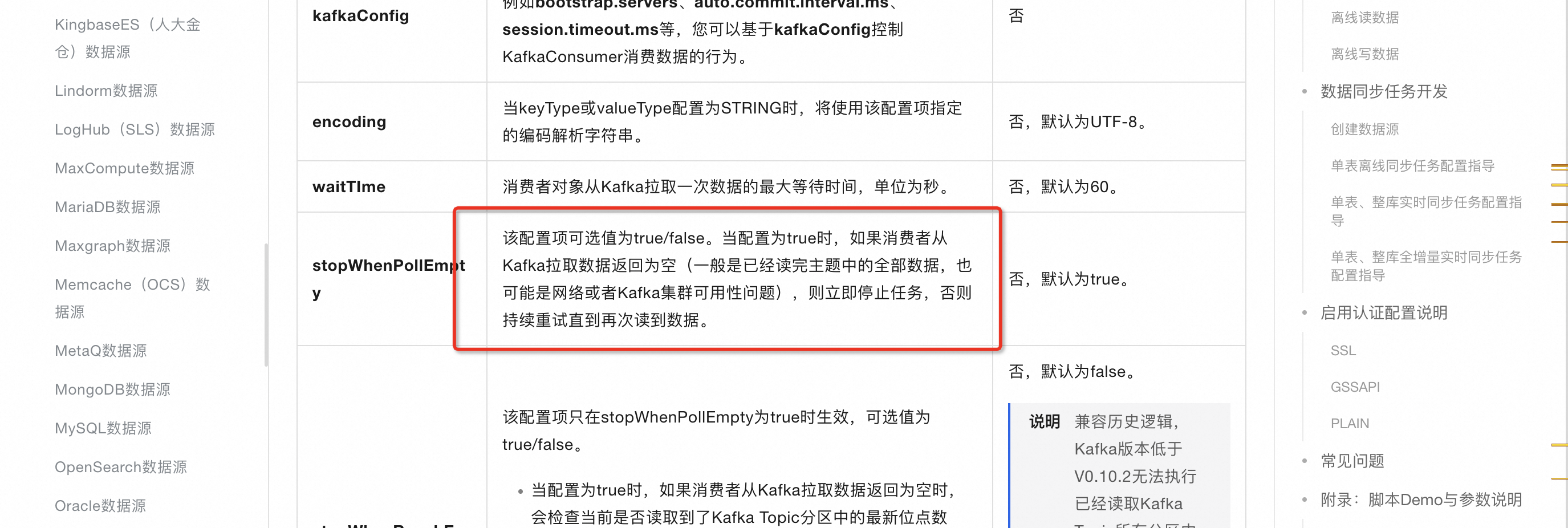
DataWorks中 kafka 数据源同步到mc , 任务一直在执行中, 选择的同步是5分钟。这种一般是什么问题呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云DataWorks中,如果你设置了从Kafka数据源同步到MaxCompute(mc)的任务,并且任务一直在执行中,即使选择的同步周期是5分钟,可能的原因有以下几点:
数据量大:
如果Kafka中的数据量非常大,特别是在短时间内产生的数据量超过了任务处理能力,可能会导致任务长时间运行。
资源不足:
MaxCompute作业或DataWorks数据同步任务可能因为计算资源不足(如CU、内存等)而无法在预期时间内完成同步。需要检查当前任务配置的资源是否足够应对实际的数据处理需求。
网络延迟或带宽限制:
Kafka与MaxCompute之间的网络连接可能存在延迟或者带宽限制问题,导致数据传输速度慢,进而影响任务执行效率。
同步逻辑复杂:
同步过程中如果涉及到复杂的转换、清洗或过滤逻辑,也可能延长任务执行时间。
并发冲突或依赖等待:
如果此任务与其他任务存在并发冲突或依赖关系,可能导致任务需要等待其他任务完成后才能继续执行。
任务配置错误:
检查任务配置是否正确,比如消费Kafka Topic的方式、分区策略、MaxCompute表结构和写入方式等,确保没有错误设置导致任务不能正常结束。
DataWorks中Kafka数据源同步到MaxCompute(MC)的任务一直在执行中,可能有以下几种原因:
任务配置错误:检查任务的配置是否正确,包括Kafka和MC的连接信息、表结构等。如果配置有误,可能会导致任务无法正常执行。
网络问题:检查Kafka和MC之间的网络连接是否正常。如果网络不稳定或者延迟较高,可能导致任务执行时间过长。
数据量过大:如果Kafka中的数据量非常大,那么同步到MC的任务可能需要较长时间来完成。可以考虑分批次同步数据,或者优化任务处理逻辑以提高执行效率。
系统资源不足:检查DataWorks和Kafka、MC所在的服务器的资源是否充足。如果资源不足,可能导致任务执行速度变慢或者失败。可以考虑增加服务器资源或者优化任务配置。
任务调度问题:检查任务的调度策略是否正确。如果任务调度策略不合理,可能导致任务一直处于等待状态。可以尝试调整任务调度策略,例如设置合理的执行频率或者优先级。
代码逻辑问题:检查任务的处理逻辑是否存在问题。如果代码逻辑有误,可能导致任务无法正常执行。可以仔细检查代码,确保逻辑正确无误。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。