
DataWorks中spark操作odps,写入时报的错,哪位大神给看看什么原因引起的?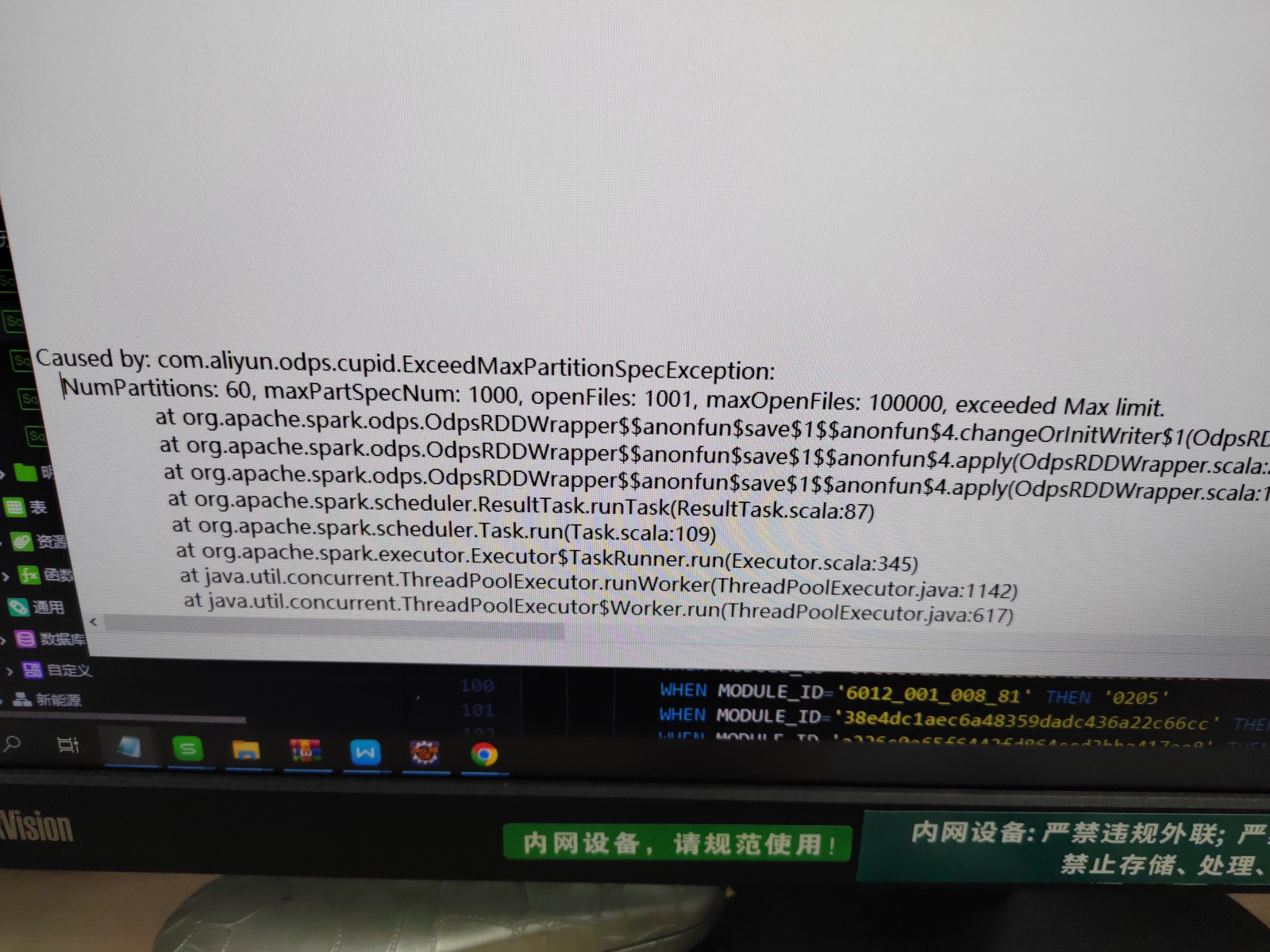
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
问题可能是由于在 DataWorks 中使用 Spark 操作 ODPS 时,生成的分区数量(NumPartitions)超过了 ODPS 的限制。在这种情况下,错误信息中提到了几个关键参数:
NumPartitions: 60
maxPartSpecNum: 1000
openFiles: 1001
maxOpenFiles: 100000
从这些参数来看,openFiles(1001)已经超过了 maxOpenFiles(100000),这说明在写入过程中,打开的文件数量已经达到了 ODPS 的最大限制。为了解决这个问题,您可以尝试以下几种方法:
调整 Spark 任务的并行度,以减少生成的分区数量。这可以通过修改 Spark 任务的配置文件来实现,例如修改 `spark.sql.shuffle.partitions` 参数。
优化您的数据处理逻辑,以减少写入操作所需的文件数量。这可能需要您对数据进行预处理,或者调整数据分区策略。
如果您使用的是 DataWorks 托管的 Spark 集群,可以联系 DataWorks 技术支持团队,看看他们是否可以为您调整 ODPS 的相关配置,以放宽文件打开数量的限制。
楼主你好,看了你的问题,这个错误是由于你的写入操作超出了阿里云DataWorks中的限制导致的,具体原因是写入的分区数超过了最大允许的分区数,超出了最大文件打开数限制。你正在使用的分区数为60,但最大分区数限制为1000,而且你已经打开了1001个文件,超出了100000个文件的最大打开数限制。
解决方法是减少分区数,确保分区数小于等于最大分区数限制,并且减少打开的文件数,确保文件数小于等于最大文件打开数限制。还可以考虑调整分区策略,减少分区数,或者增加DataWorks的可用资源配额,以增加最大文件打开数的限制。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


