
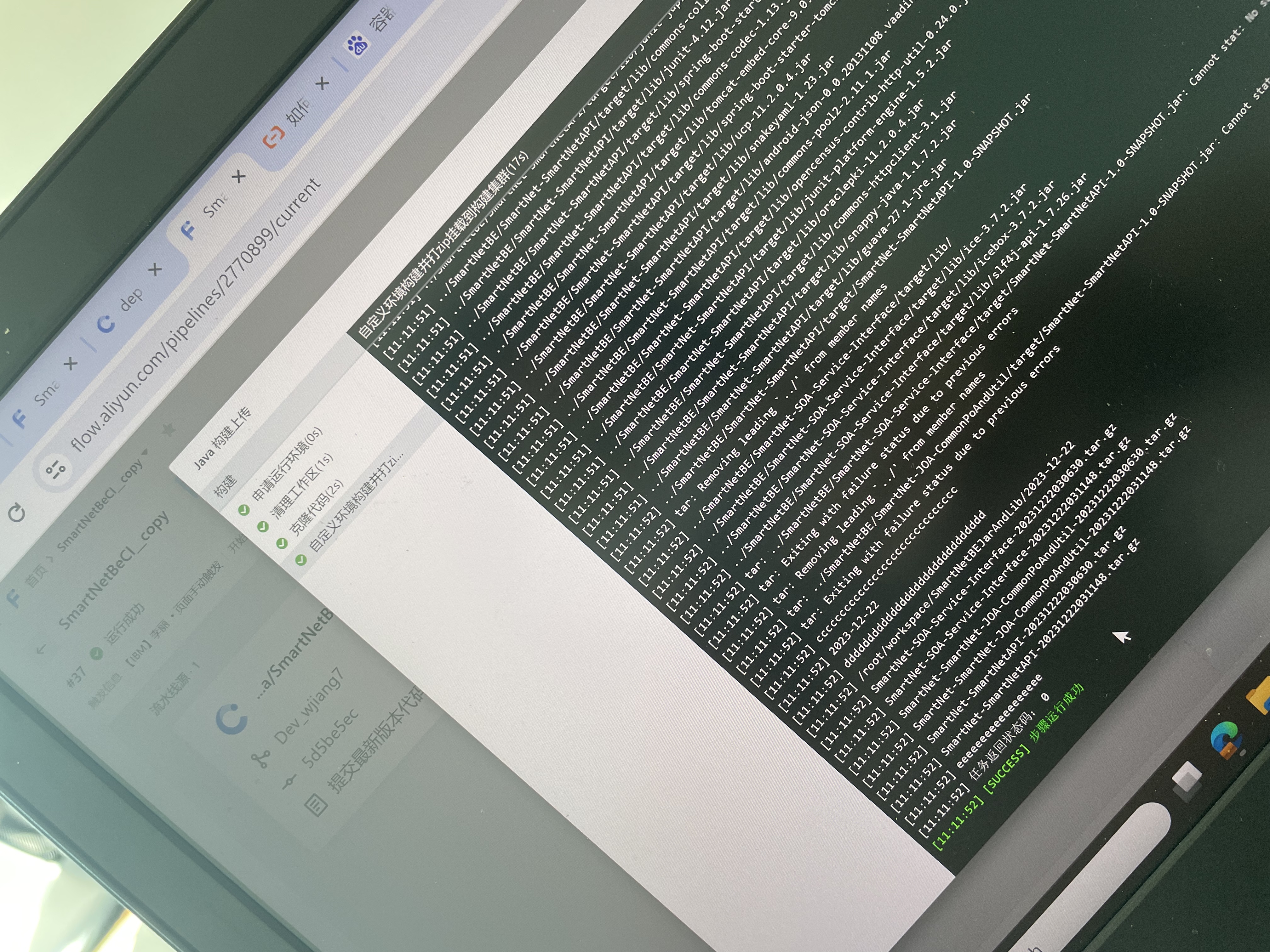
在云效另一个流水线看不到前一个流水线挂载的文件,为什么?构建机只有一台机器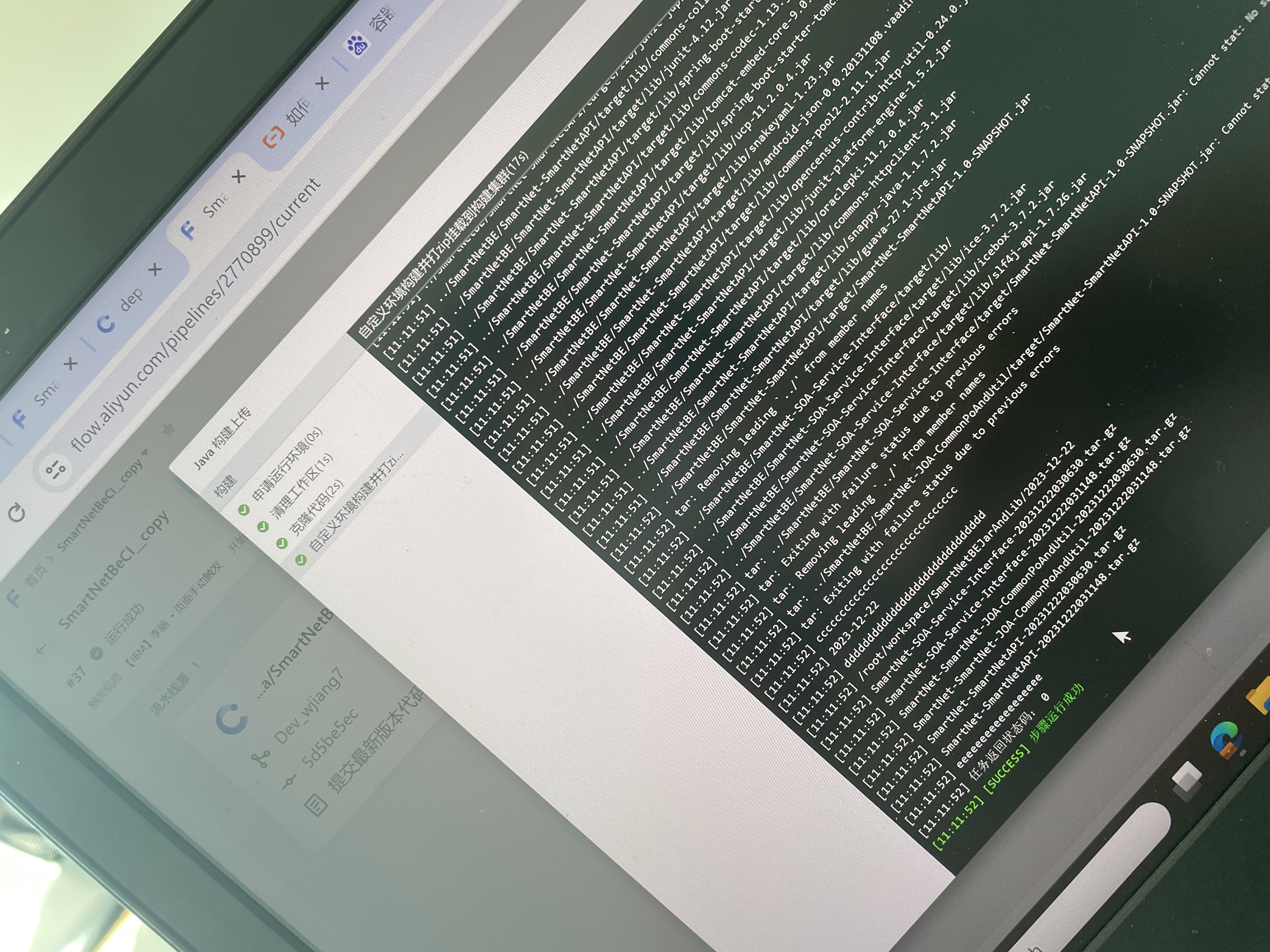
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在云效的持续集成/持续部署(CI/CD)流程中,每个流水线执行时都会创建独立的工作目录和环境变量,即使构建机只有一台,不同流水线之间仍然默认保持数据隔离。因此,一个流水线中的文件挂载并不会自动对其他流水线可见。
要实现流水线之间的文件共享或传递,你可以采取以下策略:
使用持久化存储:
将需要跨流水线共享的文件上传至阿里云对象存储服务OSS或其他持久化存储服务,并在第二个流水线中通过API或者其他方式下载这些文件作为输入。
利用中间仓库:
在第一个流水线结束时将生成的文件发布到代码仓库的一个特定分支或者标签,然后在第二个流水线上拉取并处理这些文件。
自定义脚本和环境变量:
如果在同一台构建机上运行,可以考虑通过自定义脚本来临时保存和读取公共路径下的文件,但这不是云效推荐的最佳实践,因为这种方式不具有良好的可移植性和扩展性。
流水线间依赖和触发:
设计流水线任务之间通过上下游关系来传递信息,例如:上游流水线成功后通过钉钉消息、API回调等方式告知下游流水线文件位置,下游流水线根据接收到的信息去获取相应的文件。
总之,在云效中,为了确保数据安全和环境一致性,默认不会让不同流水线直接访问彼此的数据,你需要通过额外的设计与配置实现数据的有效传递。
云效,企业级一站式研发协同平台,数十万企业都在用。支持公共云、专有云和混合云多种部署形态,通过云原生新技术和研发新模式,助力创新创业和数字化转型企业快速实现研发敏捷和组织敏捷,打造“双敏”组织,实现多倍效能提升。


