
Flink使用 jdbc_fixed 在同一批次中按照什么条件规则去重呢?我们现在发现加了这个配置后,数据不准确。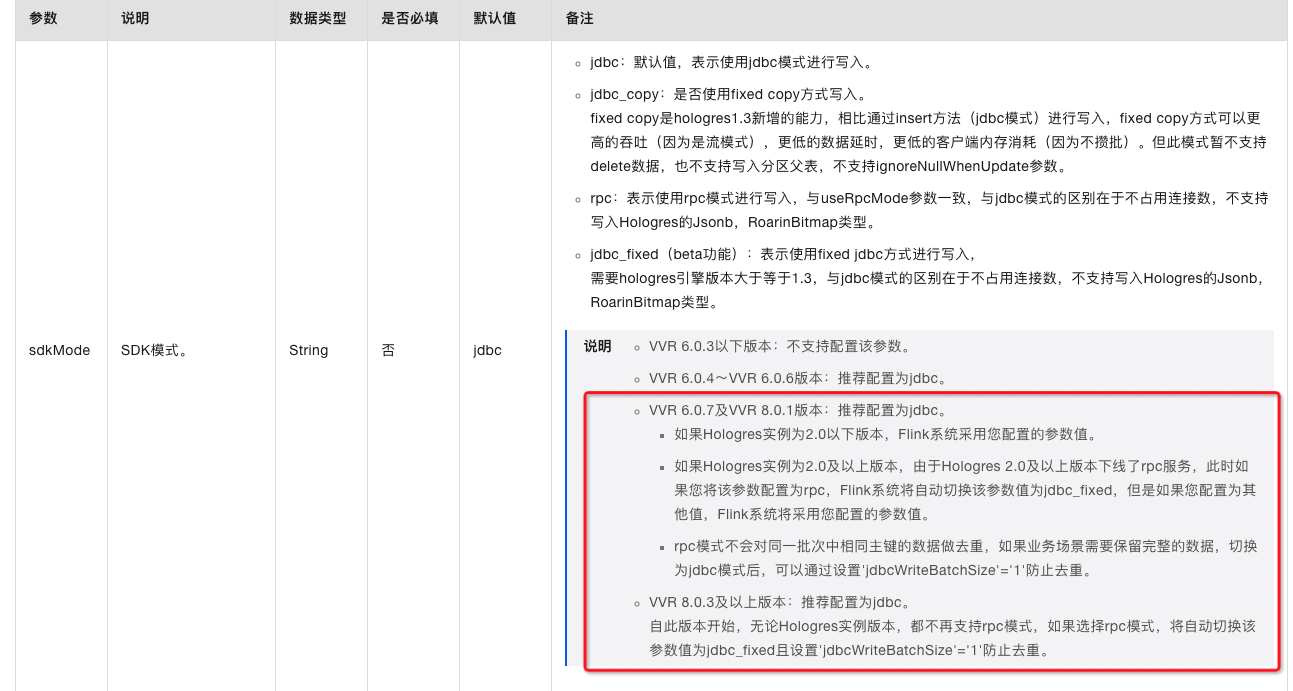
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink使用jdbc_fixed连接器时,在同一批次中按照主键字段去重。这意味着如果多个记录具有相同的主键值,则只会保留一条记录。
如果您发现添加了jdbc_fixed连接器后数据不准确,可能是由于以下原因之一:
主键冲突:如果多个记录具有相同的主键值,则只会保留一条记录。请确保您的数据源中的主键是唯一的,并且没有重复的主键值。
数据类型不匹配:请确保您的数据源中的主键字段与目标表的主键字段的数据类型相匹配。如果数据类型不匹配,可能会导致数据转换错误或丢失。
配置问题:请检查您的Flink作业配置是否正确。特别是,请确保您已正确指定了目标表的主键字段和数据源中的主键字段。
在Flink中,jdbc_fixed sink(现已更名为jdbc sink with sink.buffer-flush.max-rows配置)允许你控制批次大小来批量写入数据到数据库。但是,jdbc_fixed sink本身并不提供内置的去重功能。
如果你在使用jdbc_fixed sink时发现数据不准确,可能的原因有以下几点:
源数据重复:
如果你的源数据本身就包含重复的数据行,那么在写入数据库时,这些重复的行也会被写入。
并行处理导致的重复:
如果你的Flink作业并行度大于1,并且没有对数据进行适当的分区或者去重处理,那么同一行数据可能会被多个并行任务处理并写入数据库,导致重复。
故障恢复和 Exactly-Once 语义:
在某些故障恢复情况下,如果没有启用Exactly-Once语义或者状态后端配置不正确,Flink可能会重新处理已经成功写入数据库的数据,导致重复。
要解决这个问题,你可以考虑以下方法:
在源端进行去重:
如果源数据可能存在重复,你可以在读取数据的源头就进行去重处理。例如,使用Flink的 distinct 或者 groupBy + count 运算符。
使用KeyedStream和reduce或aggregate进行去重:
如果你的数据有可以用来唯一标识一行的键,你可以将流转换为KeyedStream,然后使用reduce或aggregate运算符进行去重。
自定义预聚合和去重逻辑:
你可以编写自定义的Flink函数或者ProcessFunction,实现更复杂的预聚合和去重逻辑。
启用Exactly-Once语义:
确保你的Flink作业启用了Exactly-Once语义,并且状态后端配置正确,以避免在故障恢复时重复处理数据。
在数据库层面进行去重:
如果以上方法都无法满足你的需求,你也可以考虑在数据库层面添加唯一约束或者使用 Upsert(插入或更新)语句来确保数据的唯一性。
去重就是指攒批的时候做不做去重,比如上游给了10条主键都是a的数据,jdbc只会写最后一条,因为大多数场景前9条没必要保留,无论如何都会被更新的;
但有些用户,就需要有这个从1到10的变化记录,这种情况就不希望去重。 这一批中最新一条,是按照进入的自然时间顺序排的。此回答整理自钉群“实时计算Flink产品交流群”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


