
Flink CDC sql 版本,mongo connector 如何提升source的消费速率?【业务背景】有一批百亿级别的数据需要同步从mongo同步到doris,存量+增量都要同步,所以想使用CDC同步,但是发现速率太慢,目前QPS 2w,预计300亿要同步20天左右才能跑完。【当前 job 现状】UI上看到QPS在2万左右,并且source的并行度一直是1。请问如何提高source的并行度?以及并行度的提升是否有助于提升消费速率?sql 的 source table 配置如下,这里在CDC文档中没有找到可以配置source并行度的地方。提高了拉数据的batch size。发现对source的QPS没有提升效果。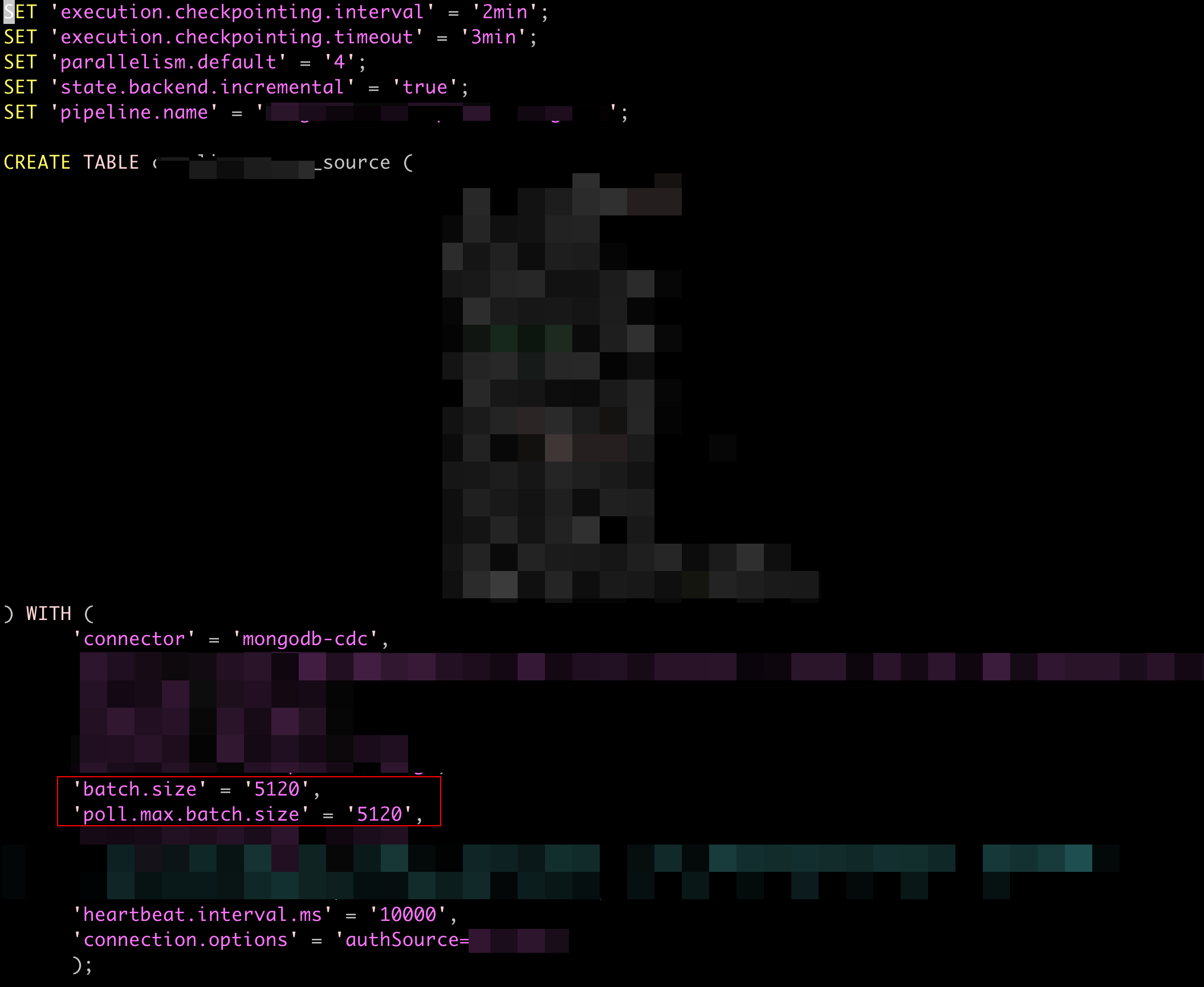
之前尝试过这样的方法,先用data X同步存量数据,再用CDC消费mongo最新的offset到doris。出现的问题是后续mongo中删除存量数据,cdc在doris中不会完成删除操作,只有cdc自己增量同步的数据跟随mongo删除。 ps: 按文档说明doris开启了批量删除,并使用了unique key表模型。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对您的问题,可以尝试以下方法来提高Flink CDC MongoDB Source的消费速率:
SET parallelism语句来设置并行度。例如,将并行度设置为4:SET parallelism.default=4;
SET table.exec.buffer-timeout和SET table.exec.max.buffer-size语句来调整batch size。例如:SET table.exec.buffer-timeout=5s;
SET table.exec.max.buffer-size=10000;
优化源表配置:确保源表的配置是最优的,例如使用合适的索引、分区等。这有助于提高查询性能,从而提高消费速率。
考虑使用其他连接器:如果当前的MongoDB Connector无法满足性能需求,可以考虑使用其他支持更高消费速率的连接器,如Debezium MongoDB Connector。
优化目标端Doris:检查Doris集群的配置和性能,确保它们能够支持高并发的数据写入。可以考虑增加Doris集群的资源或优化其配置以提高写入性能。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


