
在函数计算FC我训练lora的时候卡在这一步了,是什么原因啊?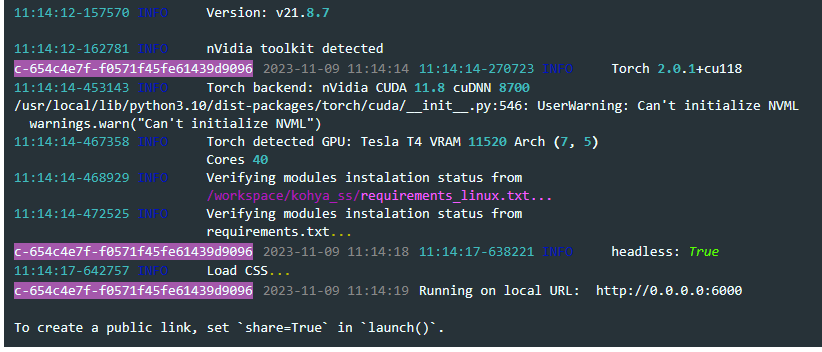
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在函数计算FC上训练LoRa时出现卡顿可能有多种原因,以下是一些常见的问题和解决方案:
GPU问题:确保您的训练数据是高质量的,并且覆盖了您想要训练的模型的所有可能情况。如果您的数据不足或者覆盖情况不足,训练可能会非常慢。
训练数据问题:确保您的训练数据是高质量的,并且覆盖了您想要训练的模型的所有可能情况。如果您的数据不足或者覆盖情况不足,训练可能会非常慢。
模型问题:确保您的模型是正确的,并且是经过训练的。如果您的模型是错误的,或者没有经过训练,训练可能会非常慢。
网络问题:确保您的网络连接是稳定的,如果网络不稳定,可能会导致训练卡顿。
系统资源问题:如果您的系统资源(如CPU、内存、磁盘空间等)不足,也可能导致训练卡顿。您可以尝试优化您的系统资源,或者使用更强大的系统。
根据您提供的信息,训练过程中出现了一个警告信息:"Can't initialize NVML"。这个警告表明在初始化NVIDIA管理库(NVML)时出现了问题。这可能是由于以下原因之一:
缺少依赖项:请确保您的系统上安装了所有必要的依赖项,包括CUDA、cuDNN和NVML。您可以从NVIDIA官方网站下载并安装这些组件。
版本不兼容:请检查您的CUDA和cuDNN版本是否与您的PyTorch版本兼容。您可以在PyTorch官方网站上找到支持的版本列表。
环境变量设置错误:请检查您的环境变量设置是否正确。特别是,确保LD_LIBRARY_PATH和PATH环境变量包含了正确的CUDA和cuDNN库路径。

