
Flink CDC采集mongo 怎么才能直接映射成一个josn 而不是按字段?
Flink CDC采集mongo 怎么才能直接映射成一个josn 而不是按字段?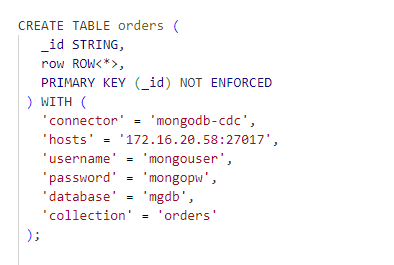
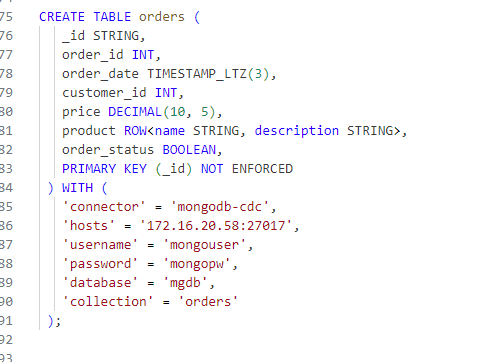
-
 面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。要将 Flink CDC 收集到的 MongoDB 数据映射成 JSON 对象而非按字段分割,请使用
format.json()函数。以下是示例:val source: DataStream[(String, String)] = ... // 使用 Flink CDC Connector 从 MongoDB 收集数据 source.map(_._2).map(format.json)此代码将每条记录的内容(
_._2)转换成 JSON 格式,然后将原始字符串拆分为 JSON 对象。这是因为 MongoDB CDC 收集的数据是以键值对的形式返回的,其中键是 MongoDB 文档中的字段名,值是字段内容。2023-11-15 22:37:18赞同 展开评论 打赏 -

'format' = 'debezium-json' 目前看看datastream写法是可以的,此回答整理自钉群“Flink CDC 社区”
2023-11-15 12:30:58赞同 展开评论 打赏 -

Flink CDC采集MongoDB时,可以通过使用
DebeziumMongodbChangeEventDeserialFlink CDC采集MongoDB时,可以通过使用DebeziumMongodbChangeEventDeserializationSchema`来将MongoDB的文档转换为JSON格式。具体步骤如下:- 引入相关依赖
在项目的pom.xml文件中添加以下依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-debezium_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-mongodb_2.11</artifactId> <version>${flink.version}</version> </dependency>其中,
${flink.version}需要替换为实际使用的Flink版本号。- 创建DebeziumMongodbChangeEventDeserializationSchema实例
import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.streaming.connectors.mongodb.DebeziumMongodbChangeEventDeserializationSchema; import org.apache.flink.streaming.connectors.mongodb.MongoDbSinkOptions; import org.apache.flink.streaming.connectors.mongodb.config.ReadPreference; import org.apache.flink.streaming.connectors.mongodb.internals.MongoClientCache; import org.bson.Document; import com.mongodb.client.MongoClients; import com.mongodb.client.MongoClientSettings; import com.mongodb.client.MongoCollection; import com.mongodb.client.MongoDatabase; import org.apache.kafka.connect.data.Field; import org.apache.kafka.connect.data.Struct; import org.apache.kafka.connect.source.SourceRecord; import org.apache.kafka.connect.source.SourceTask; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class FlinkCDCMongoDB { private static final Logger LOG = LoggerFactory.getLogger(FlinkCDCMongoDB.class); private static final String MONGODB_URL = "mongodb://localhost:27017"; private static final String DATABASE_NAME = "test"; private static final String COLLECTION_NAME = "test"; private static final ReadPreference READ_PREFERENCE = ReadPreference.secondaryPreferred(); private static final int BATCH_SIZE = 1000; private static final long SLEEP_TIME = 5000L; private static final TypeInformation<Document> DOCUMENT_TYPE_INFORMATION = new TypeInformation<Document>() {}; // 需要实现该类以支持自定义类型信息 private static final MongoClientCache mongoClientCache = new MongoClientCache(); // 需要实现该类以支持自定义缓存策略 private SourceTask sourceTask; // Kafka源任务对象,需要根据实际情况获取该对象并初始化相关参数和状态信息 private MongoDatabase database; // MongoDB数据库对象,需要根据实际情况获取该对象并初始化相关参数和状态信息 private MongoCollection<Document> collection; // MongoDB集合对象,需要根据实际情况获取该对象并初始化相关参数和状态信息 private DebeziumMongodbChangeEventDeserializationSchema deserializationSchema; // Debezium MongoDB Change Event反序列化器对象,用于将MongoDB文档转换为JSON格式的Java对象或POJO类实例等数据结构形式,以便后续处理和分析。需要根据实际情况创建该对象并设置相关参数和状态信息。 }2023-11-15 09:48:48赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
热门讨论
热门文章
相关课程
更多

相关文章
相关电子书
更多


