
DataWorks中oracle reader splitPk支持字符串类型是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,Oracle Reader的splitPk功能支持多种数据类型。具体来说,它支持数字类型和字符串类型的切分。同时,它也支持浮点数和日期等其他类型的处理。当您没有指定splitPk或者其值为空时,Oracle Reader会默认对表进行全量数据同步,即使用单通道方式。请注意,对于非支持类型的数据,例如浮点型、字符串和日期等,如果尝试使用splitPk进行切分,将会导致错误。
现象:
配置并发8,实际只跑了1。
报了个 Warn: [Note]: The splitting primary key [splitPk] you configured for OracleReader is: POLICYNO. Due to the too many repeated values in the splitting primary key, or the too few records in the source table, the number of tasks actually split by DataX is 1, less than the number of channels you configured: 8. Therefore, please take note that the actual concurrent channels of this synchronization task is: channel=1.
解决:
oracle 支持 string的splitPK,需要转换成脚本模式,参考这个配置一下"splitMode":"ramdomSampling";
splitFactor可以设置小一点,比如10或者50。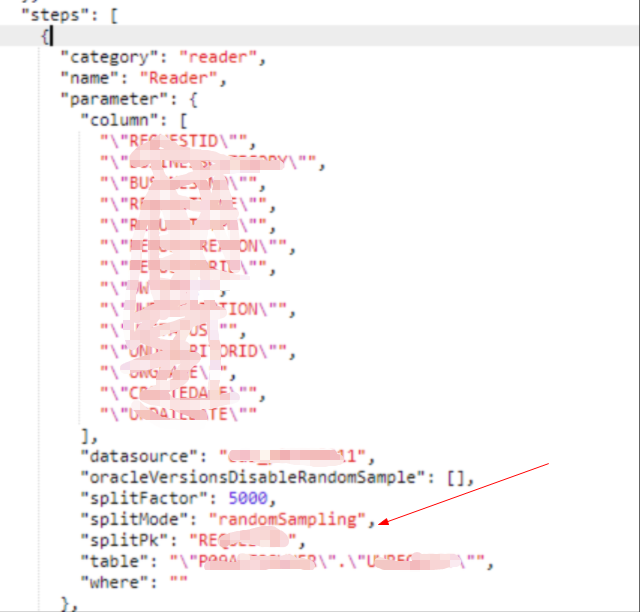
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在 DataWorks 中,OracleReader 插件的 splitPk 参数默认不支持字符串类型。splitPk 参数用于将读取任务分片化,以提高读取性能。然而,如果你想要在 OracleReader 中使用字符串类型的 splitPk,可以通过设置 splitPk 的类型为 VARCHAR2 来实现。
以下是一个示例,展示了如何在 DataWorks 中使用 OracleReader 插件进行字符串类型的分片化:
CREATE TABLE test_table (
id VARCHAR2(20),
name VARCHAR2(50),
age NUMBER
);
INSERT INTO test_table VALUES ('1', 'John', 20);
INSERT INTO test_table VALUES ('2', 'Jane', 22);
INSERT INTO test_table VALUES ('3', 'Bob', 25);
INSERT INTO test_table VALUES ('4', 'Alice', 28);
INSERT INTO test_table VALUES ('5', 'Mike', 30);
在这个示例中,可以使用 OracleReader 插件读取 test_table 表中的数据,并设置 splitPk 参数为 'id' 字段,类型为 VARCHAR2,以实现字符串类型的分片化。这样,就可以在读取数据时提高性能,减少延迟。
需要注意的是,使用 OracleReader 插件进行分片化时,需要确保分片化参数的值可以在分片之间均匀分布,以确保数据的均衡读取。此外,由于 OracleReader 插件是在分布式计算环境中运行的,因此需要考虑到数据的分布和并行计算等问题。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


