
DataWorks输入输出和代码血缘分析不匹配?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当您在DataWorks中配置输入和代码血缘分析时,如果输入输出和代码血缘分析不匹配,可能是由于以下原因:
【血缘关系】
表间数据来源与去向,即节点中表select和insert关系。
【血缘关系解析】
代码中select的表自动解析将作为节点输入;
代码中insert的表自动解析将作为节点输出。
【用户提交的输入输出】
用户提交的输入:在调度配置界面的解析出父节点id的输出名(表)。
用户提交的输出:在调度配置界面的本节点的输出名称(表)。
【血缘关系解析的输入输出与用户提交的输入输出不匹配提示】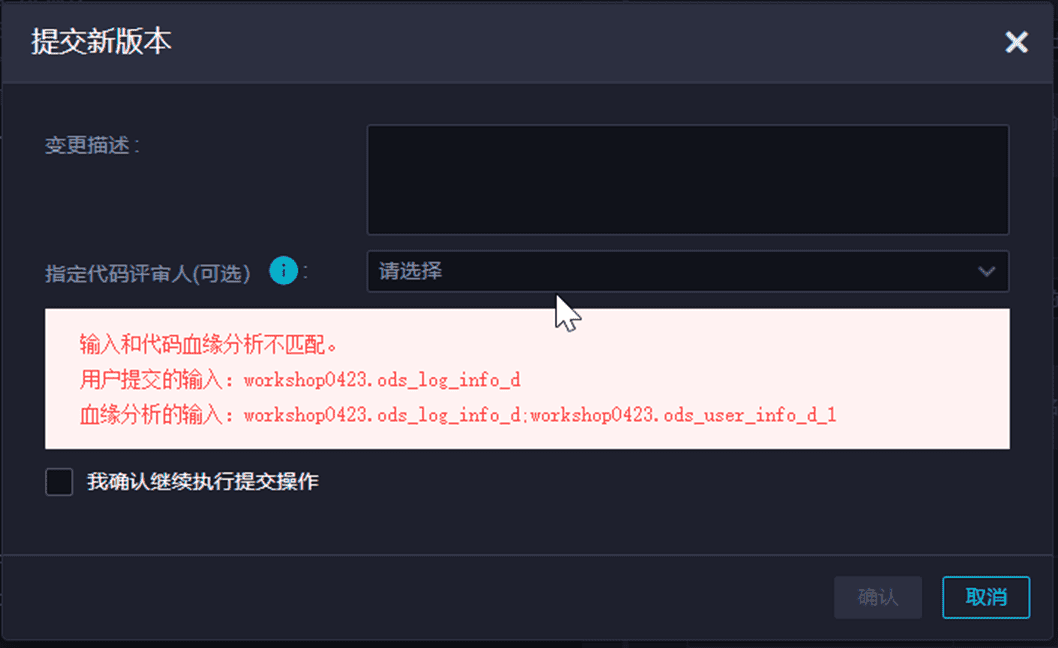
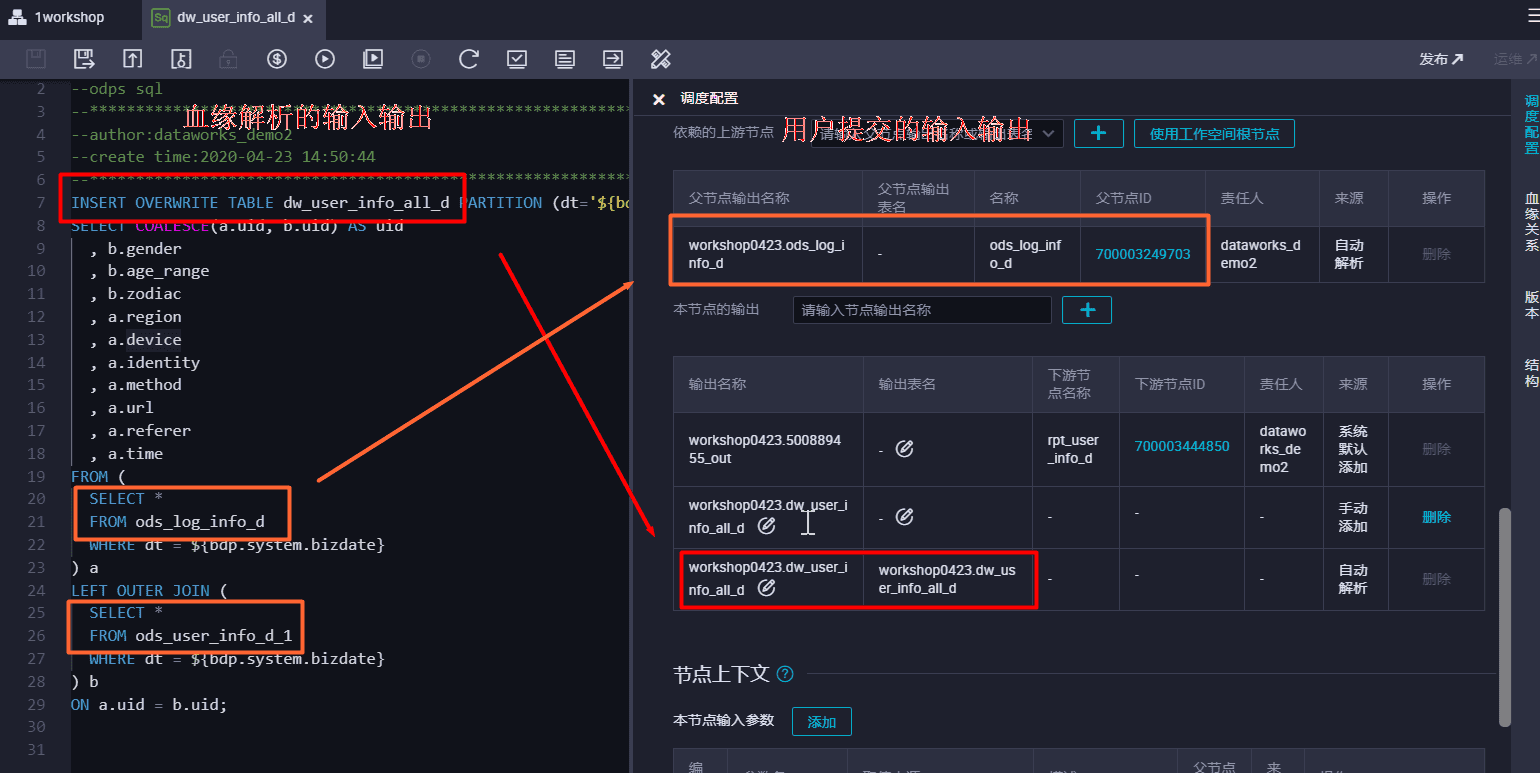
如果提示用户提交输入和代码解析的不匹配,请确认表否需要依赖该表:
需要依赖该表:检查产出该表数据的节点是否将该表作为节点输出(同步任务需要手动添加产出表未节点输出)。
不需要依赖该表:本地上传的表可忽略提示,提交节点。
【相关语料】
回复机器人:调度依赖,依赖的父节点输出不存在
注意:语料内容仅供参考,请以官网文档为准。
数据地图表血缘关系:
1)view:视图的血缘,(其上游血缘)这个是会尝试解析视图的生成语句,成功就会展示,但是有可能会失败,这个目前没有办法保证。下游的话,会根据任务来解析的(视图存在 就会尝试解析视图的生成语句 无论上游表是否存在)。
2)table: 是需要有周期调度任务来产出血缘的,在开发环境中跑的任务,不会真正纳入到血缘统计进来的,血缘是离线的 生产跑成功一次后,次日凌晨展示。,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


