
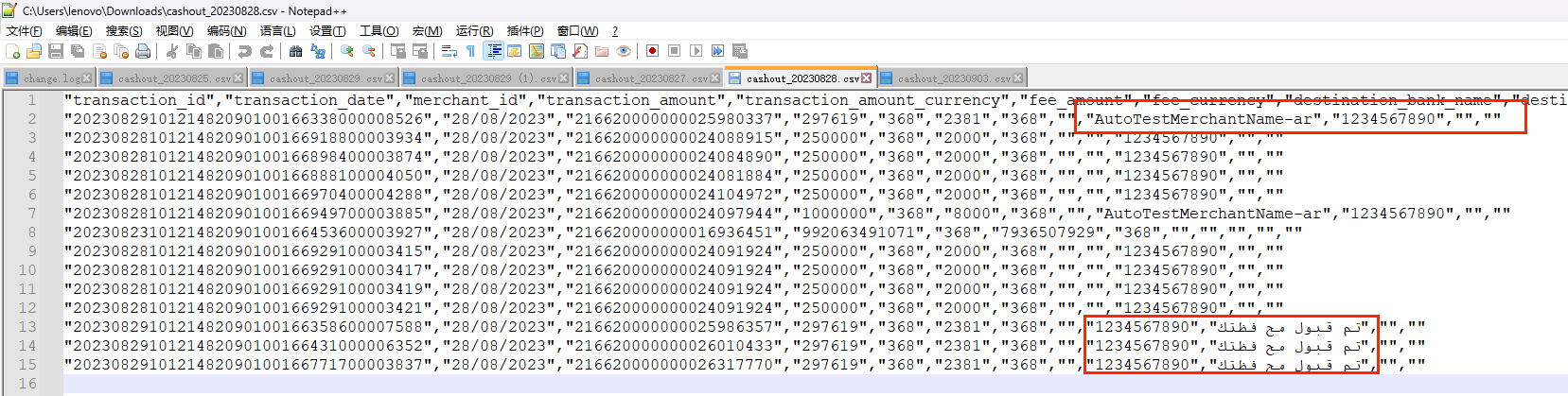
DataWorks我们这个导出文件的过程中发现部分行字段顺序乱了 能是什么原因 数据本身是对的 而且绝大多数是对的 就几条不一样 ?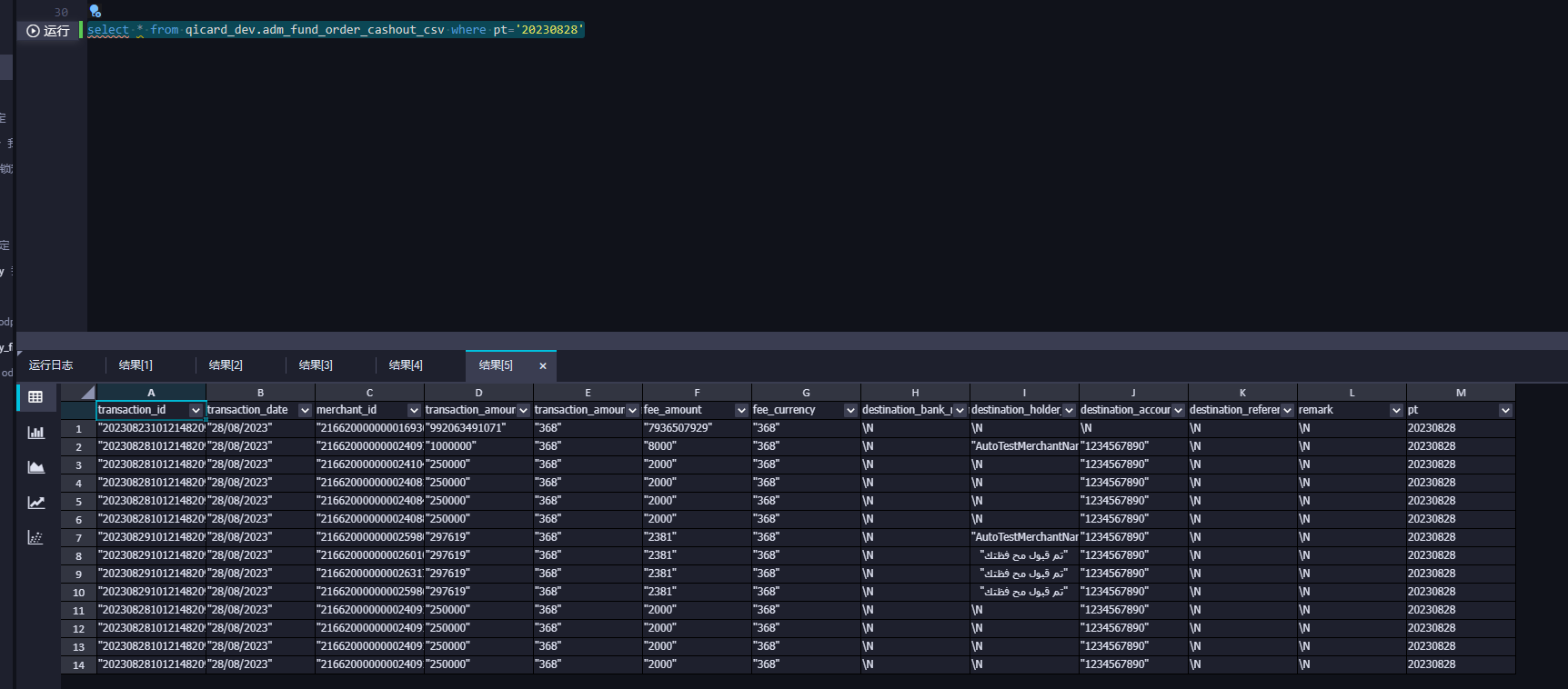
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks导出文件的过程中,如果发现部分行字段顺序乱了,而数据本身是正确的且绝大多数行的字段顺序正常,可能的原因和解决方案如下:
ORDER BY子句对数据进行排序。例如:
SELECT * FROM your_table ORDER BY your_column LIMIT n;
_before_image_和_after_image_字段的定义可能会影响数据的展示顺序。UPDATE操作,增量数据记录中可能会包含更新前后的记录,导致部分行字段顺序异常。_before_image_和_after_image_字段的处理逻辑符合预期。部分行字段顺序异常的原因可能涉及MaxCompute表的无序读取特性、行模式导出的特性、字段映射配置问题、数据预览限制、增量数据同步的影响以及黑名单或导出范围配置问题。建议根据上述分析逐一排查,并采取相应的解决方案。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

