
请问flink sql 1.15 不能引入阿里的flink-connector-clickhouse?
环境说明:flink sql 1.15 on yarn 模式
现在需要去读取kafka的数据,然后写入clickhouse。
在网上查了可以添加阿里的如下依赖文件:
com.aliyun
flink-connector-clickhouse
1.12.0
但添加这个文件失败报如下错误:
Failure to find com.aliyun:flink-connector-clickhouse:jar:1.12.0 in http://10.16.66.237:8090/repository/maven-public/ was cached in the local repository, resolution will not be reattempted until the update interval of nexus has elapsed or updates are forced
请问下这个依赖在哪里可以下载?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
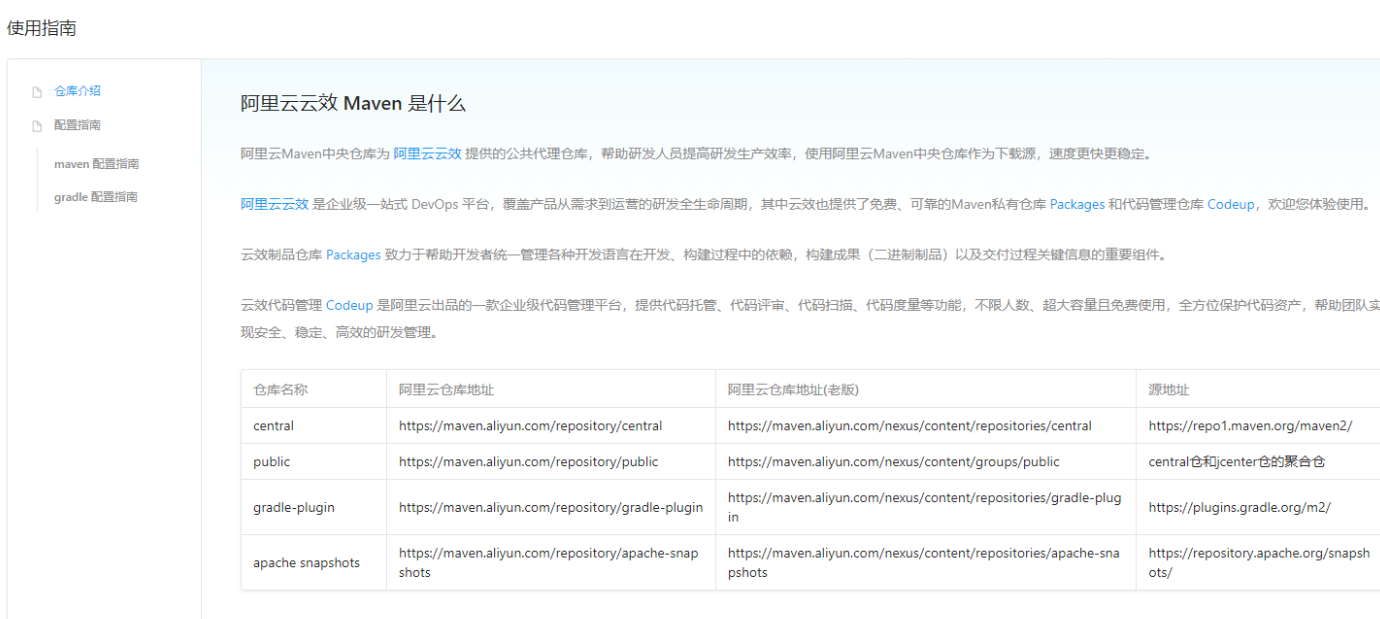
建议您查看一下阿里云的 Maven 仓库,确认是否存在与您所需版本对应的 flink-connector-clickhouse 依赖。可以搜索 flink-connector-clickhouse 关键字来查找相关依赖。
根据您提供的信息,您想在 Flink SQL 1.15 版本中使用阿里云的 flink-connector-clickhouse 插件,但是在添加依赖时遇到了问题。
从错误信息来看,您尝试从 Nexus Maven 仓库下载 com.aliyun:flink-connector-clickhouse:jar:1.12.0 的依赖失败。这可能是因为您的项目的 Maven 配置没有正确指向可用的 Maven 仓库,或者所使用的 Maven 仓库没有该依赖的版本。
关于阿里云的 flink-connector-clickhouse 插件,可以尝试从阿里云的 Maven 仓库中获取依赖。阿里云的 Maven 仓库地址为:
https://developer.aliyun.com/mvn/guide
请确保您的 Maven 配置文件(settings.xml)中包含了上述 Maven 仓库地址,并且配置正确。
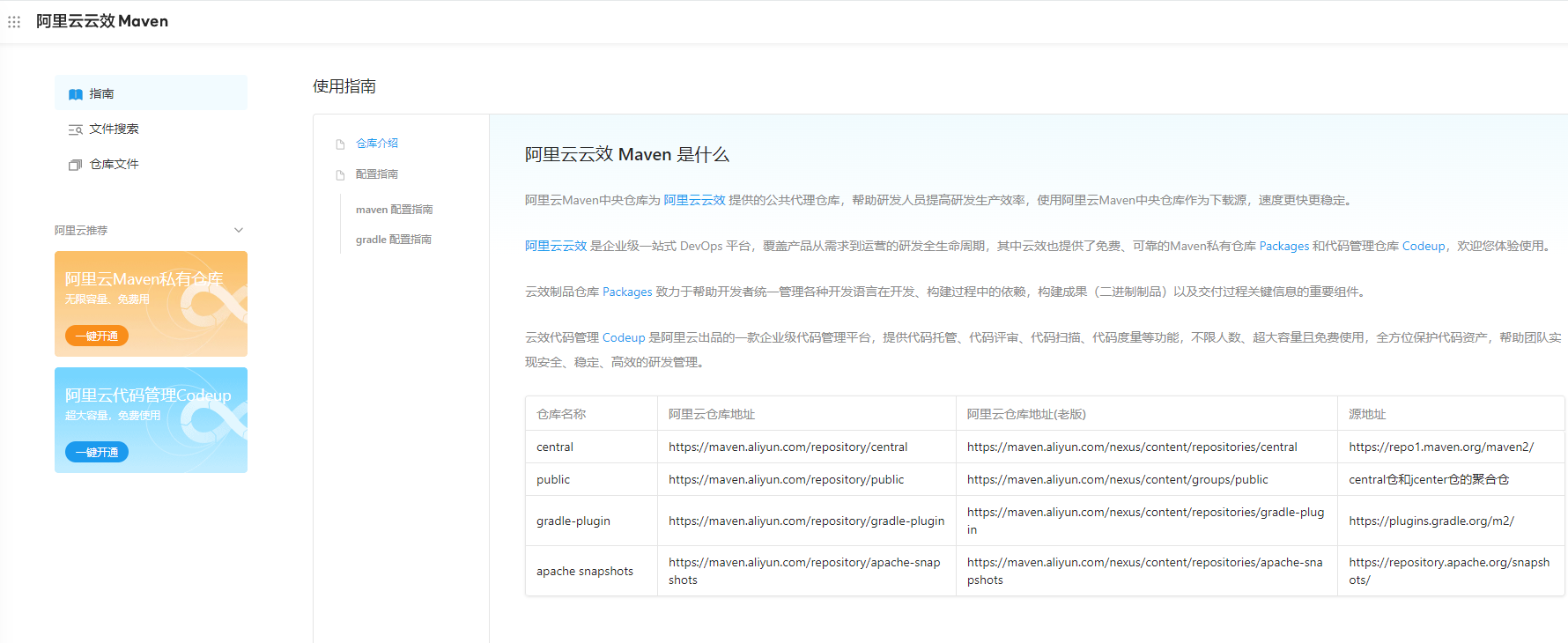
另外,建议您查看一下阿里云的 Maven 仓库,确认是否存在与您所需版本对应的 flink-connector-clickhouse 依赖。可以搜索 flink-connector-clickhouse 关键字来查找相关依赖。
如果无法在阿里云的 Maven 仓库中找到相应的依赖,您还可以尝试搜索其他 Maven 仓库,如 Maven Central Repository (https://mvnrepository.com/ ),以查找符合您需求的 flink-connector-clickhouse 依赖。
您可以在您的 Flink SQL 1.15 项目中添加阿里云的 flink-connector-clickhouse 依赖。在您的 pom.xml 文件中添加以下依赖:
请注意,您可能需要根据您的需求调整版本号。在添加依赖之后,确保重新构建并运行您的项目。
另外,关于读取 Kafka 数据并写入 ClickHouse,您可以在 Flink SQL 中创建一个 Kafka 数据源,然后使用阿里云的 flink-connector-clickhouse 将数据写入 ClickHouse。以下是一个简单的示例:
CREATE TABLE kafka_source (
id INT,
name STRING,
age INT
)
ENGINE = KAFKA()
DUPLICATE KEY(id)
BOUND BY RANGE(0, 10000)
;
CREATE TABLE clickhouse_sink (
id INT,
name STRING,
age INT
)
ENGINE = clickhouse()
;
INSERT INTO clickhouse_sink
SELECT * FROM kafka_source;
这个示例中,我们首先创建了一个名为 kafka_source 的表,该表从 Kafka 数据源中读取数据。

