
我在阿里云E-MapReduce woker节点直接 执行 jindo fs -load -meta -data -s -R -replica 1 jindo:///hadoop 看dataset 缓存成功,这具体是那一快配置有问题,还是其他原图导致的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这里你不是按照我文档上来操作的吧,dataload yaml写成上面的条件是 path: "/",否则需要指定带挂载点的路径https://github.com/aliyun/alibabacloud-jindodata/blob/master/docs/user/4.x/4.6.x/4.6.9/jindofsx/jindo_fluid/jindo_fluid_oss_ufs_example.md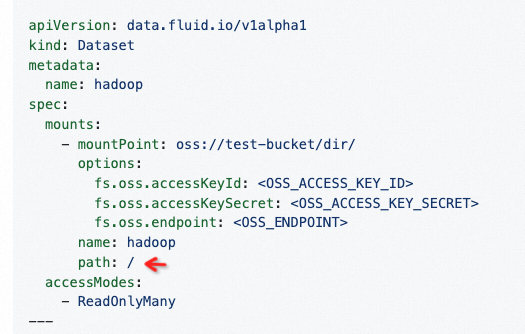
https://github.com/aliyun/alibabacloud-jindodata/blob/master/docs/user/4.x/4.6.x/4.6.9/jindofsx/jindo_fluid/jindo_fluid_dataload.md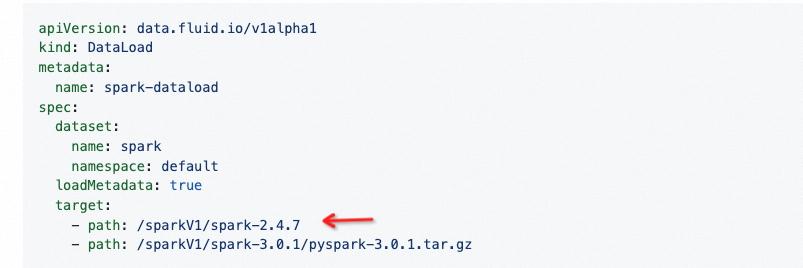
,此回答整理自钉群“JindoData 用户交流群”
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。

{kind=link}
{kind=link}