
你好,空吗? 有个大数据计算MaxCompute问题想请教你一下,我们这边有个任务是 将maxcompute数仓的项目从新加坡节点 迁移至 雅加达节点,请问你这边有什么文档可以分享一下吗? 我看了一下 maxcompute帮助文档有篇这个https://help.aliyun.com/zh/maxcompute/user-guide/maxcompute-data-migration?spm=a2c4g.11186623.0.0.cf234f129LVeo6 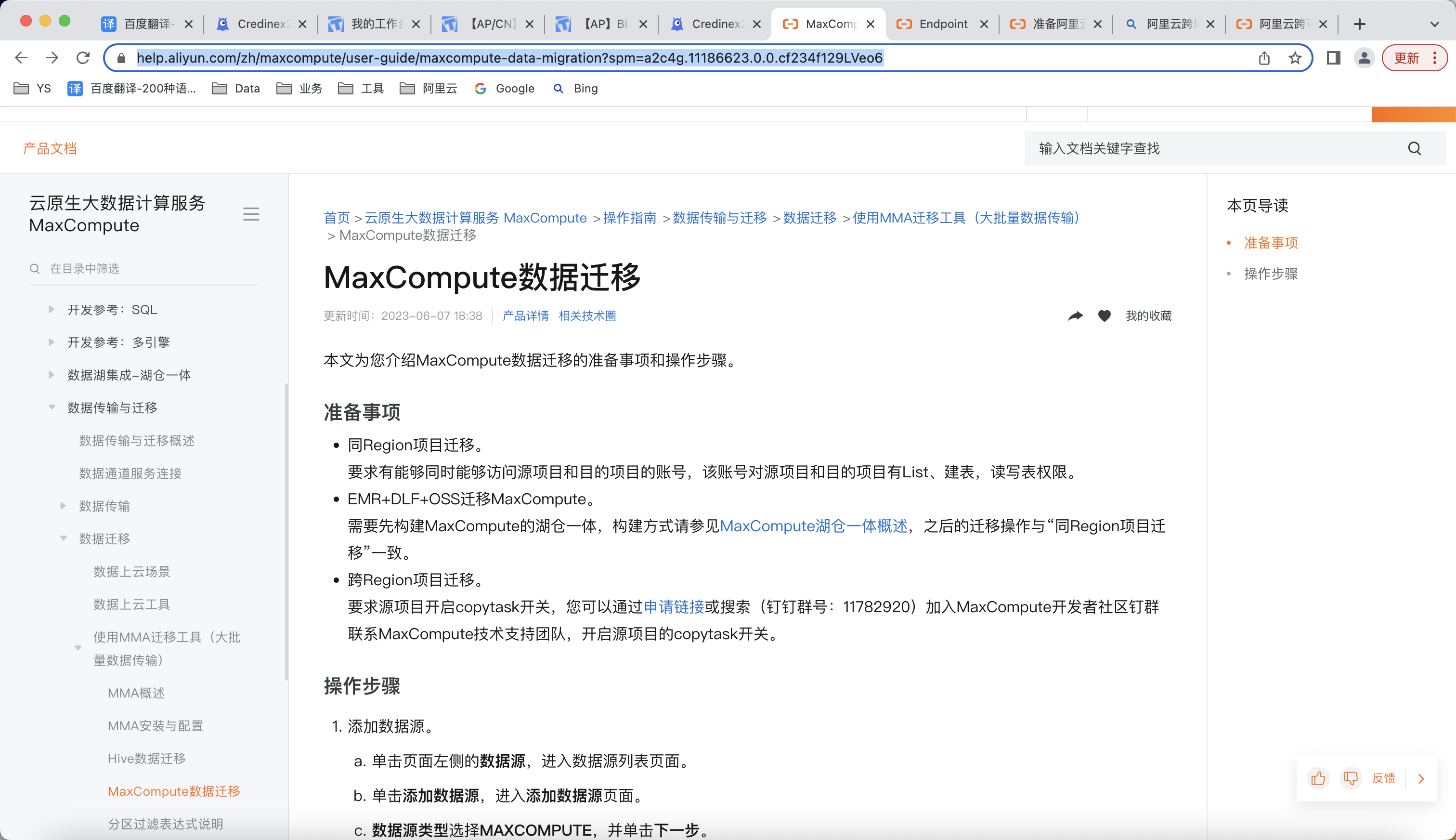
还请你帮忙看一看 按照这个文档操作的话, 能不能 把这个任务(maxcompute数仓的项目从新加坡节点 迁移至 雅加达节点)解决掉
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
以参考以下步骤:
首先,确保你有权限访问和管理MaxCompute项目,并且在新加坡和雅加达节点都有相应的资源。
在新加坡节点上,使用SHOW PROJECTS;命令列出当前可用的项目,记录你想要迁移的项目名称。
在雅加达节点上,使用CREATE PROJECT project_name;命令创建一个新项目,其中"project_name"为你想要迁移的项目名称。
在新加坡节点上,使用SHOW TABLES IN project_name;命令列出要迁移的项目中的表。
对于每个要迁移的表,在新加坡节点上,使用DESCRIBE table_name;命令查看表的结构,并记录表的模式和分区信息。
在雅加达节点上,使用相同的模式和分区信息创建相应的表。你可以使用类似下面的命令:
pgsql
Copy
CREATE EXTERNAL TABLE table_name (
column1 datatype,
column2 datatype,
...
)
PARTITIONED BY (partition_column datatype)
STORED AS PARQUET
LOCATION 'oss://your_bucket/your_path';
```
其中,"table_name"是表的名称,"column1"、"column2"是表的列名和数据类型,"partition_column"是分区列的名称和数据类型,"oss://your_bucket/your_path"是新表的存储位置。
在新加坡节点上,对于每个要迁移的表,使用INSERT INTO new_table SELECT * FROM old_table;命令将数据从旧表复制到新表。确保你在新加坡节点上具有足够的权限和资源来执行这些操作。
确保数据迁移完成后,验证新表中的数据是否正确。
迁移的话有DataWorks节点/任务 和 MaxCompute表数据这两部分
dw上的节点和任务,可以通过DataWorks的迁移助手导出旧project 和 导入新project,这里有个限制,不同版本的DataWorks有不同的支持策略,详情麻烦参考下这篇文档:https://help.aliyun.com/zh/dataworks/user-guide/create-and-view-export-tasks?spm=a2c4g.11186623.0.0.3e9f2066JU3tjX
MaxCompute上的表以及数据这部分,有两个方式,可以看需求选择用哪个。
如果表不多的情况下,可以重新建表,然后基于跨项目访问,通过insert select语法写入表数据,这个不用搭环境,走通权限问题后,执行SQL就可以。
如果表很多,可以走mma进行迁移,mma需要基于ecs搭一套环境,迁移任务需要跑在这个环境里。
如果用mma的方式,跨region迁移需要源项目开启copytask开关,需要您project name发我下,我这边走一下申请。,此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


