
问题1:Flink CDC中debezium采集的原始json数据能自定义吗?比如新增一个uuid字段而不是去修改数据表结构。
问题2:这个不是反序列化嘛,现在是想在原数据里头加个字段呢。举个例子,一个request请求做的crud动作,我需要在flinkcdc读取数据时加上这次请求的context信息。但是又不能去修改数据库。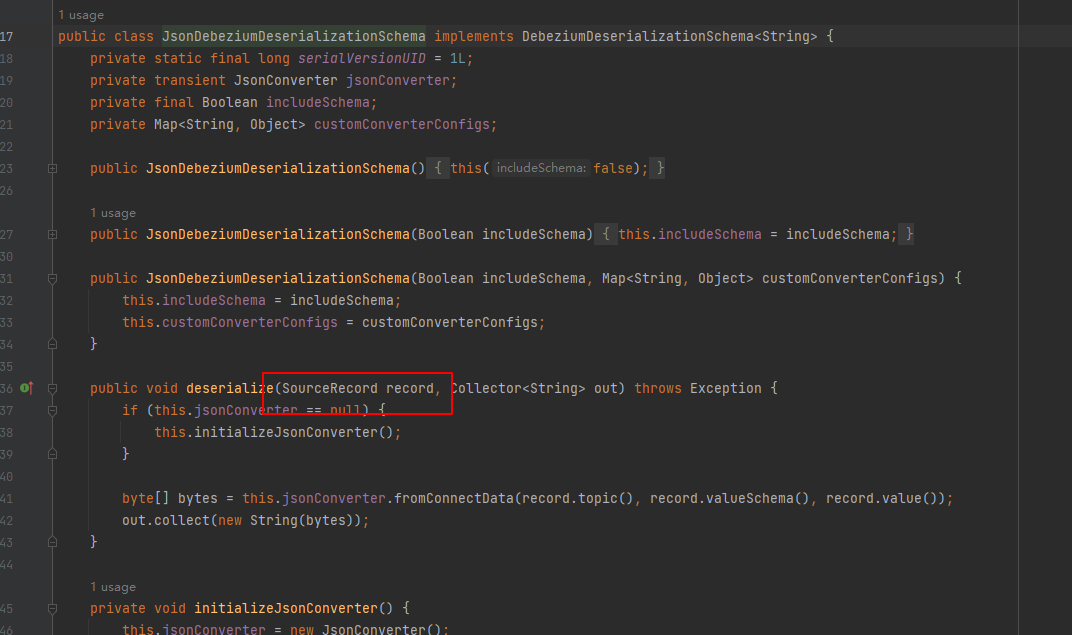
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink CDC 中,Debezium 采集的原始 JSON 数据可以通过自定义序列化器来进行自定义。Debezium 采集的原始 JSON 数据是以 Map 的形式表示的,其中键值对表示数据的列名和值。
如果要对采集的 JSON 数据进行自定义,可以实现自己的序列化器,并在 Flink CDC 应用程序中进行配置。以 Flink Table API 为例,可以通过以下方式进行配置:
java
Copy
// 创建 TableEnvironment
TableEnvironment tEnv = TableEnvironment.create(env);
// 创建 CDC 数据源
DebeziumJsonDebeziumDeserializationSchema deserializer = new DebeziumJsonDebeziumDeserializationSchema(
TypeInformation.of(new TypeHint>() {}), // 指定数据类型
new JsonNodeDeserializer(), // 指定 JSON 反序列化器
false, // 不返回 Debezium 内部字段
Collections.emptyList(), // 不返回特定的列
Collections.emptyMap() // 不返回特定的列
);
// 创建自定义序列化器
SerializationSchema serializer = new MyCustomTypeSerializationSchema();
// 创建 CDC 数据源
DataStreamSource> stream = env
.addSource(new FlinkCDCSource(
"mysql-binlog",
MySQLSource.builder()
.hostname("localhost")
.port(3306)
.username("root")
.password("")
.databaseList("mydb")
.tableList("mytable")
.deserializer(deserializer)
.build(),
StartupOptions.latest()
));
// 将采集的数据转换为自定义类型并输出
tEnv.fromDataStream(stream)
.map(new MapFunction, MyCustomType>() {
@Override
public MyCustomType map(Map value) throws Exception {
// 将采集的数据转换为自定义类型
return MyCustomType.fromMap(value);
}
})
.addSink(new FlinkKafkaProducer<>(
"my-topic",
serializer,
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
));
在这个例子中,我们通过自定义序列化器 MyCustomTypeSerializationSchema
"回答1:可以。参考,改造他。
https://blog.csdn.net/epitomizelu/article/details/121944023
回答2:这个不行吧,flink cdc只读取数据库的变更,每次请求的context信息又不落库。
source的ttl走的是状态,基本也不会太大。
此回答整理至钉群“Flink CDC 社区”"
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


