
文字识别OCR的这种表格自定义kv模版怎么定义的?我想知道如何自定义表单字段通过标注训练?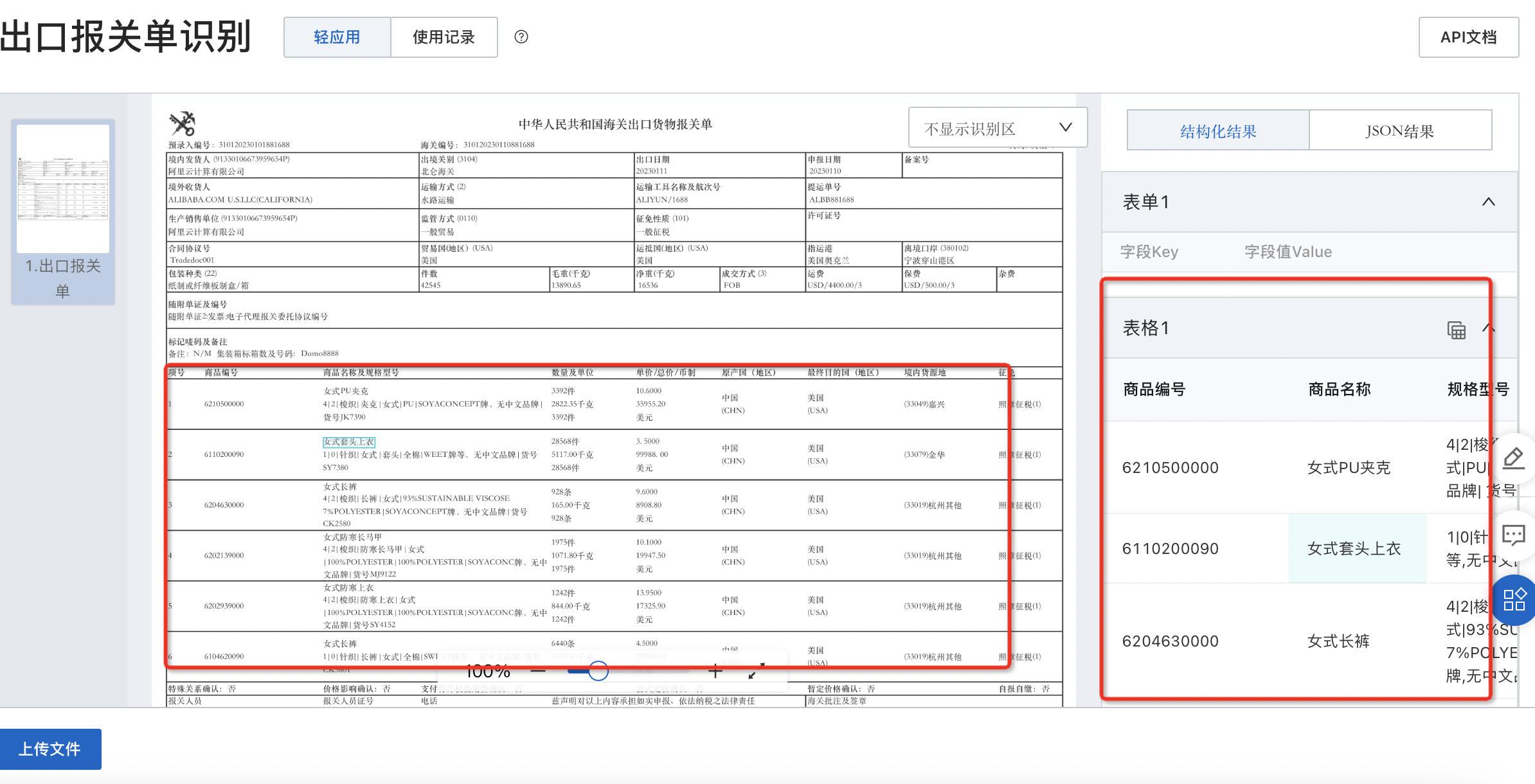
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云的文字识别OCR服务中,自定义表单的字段通过标注和训练来实现。
创建自定义模板:登录阿里云控制台,进入“文字识别OCR服务”页面,选择“自定义模板”功能,创建一个新的自定义模板。
上传示例表单图片:选择一个包含表单字段的示例表单图片,上传到自定义模板中。这个示例图片要尽可能多地包含您想要提取的各种不同类型的字段。
标注表单字段:在上传的示例表单图片上,按照表单的结构,标注出各个字段的位置和种类。您可以使用矩形框、多边形等方式进行标注。
确定字段类型:根据实际情况,为每个字段指定相应的字段类型,如姓名、日期、金额等。
进行训练:通过点击训练按钮,开始训练自定义模板。训练过程会使用标注好的数据进行模型训练,以学习如何识别表单字段。
测试和调整:训练完成后,您可以上传其他表单图片进行测试,看模型是否能够正确地提取出您指定的表单字段。如果结果不理想,您可以对标注和训练数据进行调整,并重新进行训练。
文字识别OCR的这种表格自定义kv模版通常是通过标注数据来实现的。具体来说,您需要先准备一组标注数据,其中包含了您想要识别的表格数据和对应的标签。然后,您可以使用OCR技术对这些标注数据进行训练,以生成一个能够识别表格数据的模型。
在训练模型时,您需要定义一个kv模版,用于描述每个表格字段的名称和值。例如,如果您有一个包含姓名、年龄和性别三个字段的表格,您可以定义一个kv模版。
在训练模型时,您需要将这个kv模版传递给OCR技术,以指导模型的训练过程。具体来说,您需要将每个标注数据的标签和对应的kv模版一起传递给OCR技术,以指导模型的训练过程。
文字识别 OCR 的表格自定义 KV 模板通常是通过使用自然语言处理(NLP)技术和机器学习模型来实现的。具体来说,您可以使用 Python 中的自然语言处理库(例如NLTK、spaCy、TextBlob 等)来处理输入文本,并将其转换为适合训练模型的特征向量。然后,您可以使用机器学习算法(例如朴素贝叶斯、支持向量机、神经网络等)来训练模型,以识别表格中的单元格内容。
自定义表单字段通过标注训练的方法取决于您使用的 OCR 系统和训练数据集。通常,您需要使用标注工具(例如画图软件、标注软件等)来手动标注训练数据集中的每个单元格。然后,您可以使用 OCR 系统提供的 API 将标注的数据与图像数据相结合,并使用训练算法来训练模型。在训练完成后,您可以使用模型来识别未知表格中的单元格内容。
对于文字识别OCR中的表格自定义kv模版,可以通过以下步骤来定义和训练自定义表单字段:
确定字段类型:首先,确定你需要识别的表单字段的类型,例如姓名、地址、日期等。
创建模版:在文字识别OCR服务中,创建一个新的表格自定义kv模版。给模版起一个名称,并设置相关的参数和配置。
标注训练数据:准备包含所需字段的训练数据集。对于每个表单样本,使用图像标注工具进行标注,将字段框选出来,并指定字段类型。
训练模型:将标注的训练数据集导入到OCR服务中,使用OCR的训练功能进行模型训练。训练过程将根据训练数据集学习识别表单字段。
调整和优化:根据训练结果,检查并调整模版的配置参数,以提高字段识别的准确性。可以进行多次训练和优化,直到满足需求为止。
需要注意的是,不同的OCR服务提供商可能会有不同的具体步骤和操作方式,你可以参考相应服务提供商的文档和指南,详细了解如何自定义表单字段和进行训练。
要自定义文字识别OCR的表格kv模板并通过标注进行训练,通常需要以下步骤:
收集样本数据: 首先,您需要收集包含您想要提取的字段的表格样本数据。这些数据可以是扫描的或手动创建的表格图像,确保它们涵盖了各种可能的情况和格式。
定义模板结构: 根据您的需求,定义表格模板的结构。确定您希望从每个表格中提取哪些字段,并为每个字段指定名称、数据类型和其他属性。例如,字段名称可以是"姓名"、"日期",数据类型可以是文本、数字等。
标注样本数据: 使用OCR工具或相关平台,对收集到的表格样本数据进行标注。针对每个表格,手动标注出每个字段的位置和范围,以及相应的标签。这样,系统会学习如何根据标签提取字段的内容。
训练模型: 将标注的样本数据用于训练模型。使用机器学习算法和OCR技术,模型将学习如何识别并提取表格中指定字段的内容。具体的训练过程可能需要使用OCR服务提供商提供的API或工具。
验证和优化: 对训练后的模型进行验证和测试,确保它能够准确地提取表格字段。如果发现有误差或不准确的情况,可以调整模板结构、重新标注样本数据,并重新训练模型。
要自定义表格的键值(key-value)模板,您可以通过以下步骤进行标注和训练:
准备训练数据集: 为了自定义表格的键值模板,您需要准备包含不同样式和结构的表格图像数据。这些图像应该代表您希望模型学习并识别的各种表格布局和字段。
标注表单字段: 使用标注工具或软件,对每个表单字段进行手动标注。在每个表格图像中,标注出表格中的键和对应的值字段。确保正确标注每个字段的位置、边界框或其他相关信息。
生成训练数据集: 根据标注的结果,生成训练数据集。这可以是一个数据集文件,其中包含每个表格图像及其相应的键值字段标注信息。
训练模型: 使用已标注的训练数据集,采用OCR训练算法来训练模型。根据您选择的OCR框架或库,有多种训练算法可供选择。训练过程将利用标注数据来学习表格的键值模式和结构。
评估和调整: 在训练完成后,使用一些测试数据对模型进行评估。检查模型在新的表格图像上的键值识别效果,并根据需要进行调整和改进。这可能包括优化训练参数、重新标注数据以及增加更多的训练样本等。
部署和应用: 在模型训练和调整完成后,您可以将其部署到生产环境中,并使用它来自动识别和提取表格中的键值信息。
文本字段
对于文本字段,您可以使用矩形框标注法进行训练。在标注训练时,需要将每个文本字段用矩形框框出来,并给每个字段添加相应的标签,例如姓名、地址、电话等。在训练时,OCR引擎会根据标注信息来识别表格中的文本字段。
数字字段
对于数字字段,可以使用数字框标注法进行训练。在标注训练时,需要将每个数字字段用数字框框出来,并给每个字段添加相应的标签,例如价格、数量、日期等。在训练时,OCR引擎会根据标注信息来识别表格中的数字字段。
日期字段
对于日期字段,可以使用日期框标注法进行训练。在标注训练时,需要将每个日期字段用日期框框出来,并给每个字段添加相应的标签,例如出生日期、签约日期等。在训练时,OCR引擎会根据标注信息来识别表格中的日期字段。
多选框字段
对于多选框字段,可以使用多选框标注法进行训练。在标注训练时,需要将每个多选框字段用多选框框出来,并给每个字段添加相应的标签,例如性别、婚姻状况等。在训练时,OCR引擎会根据标注信息来识别表格中的多选框字段。
像这种列表型表格的话需要用自定义表格模版或者表格信息抽取。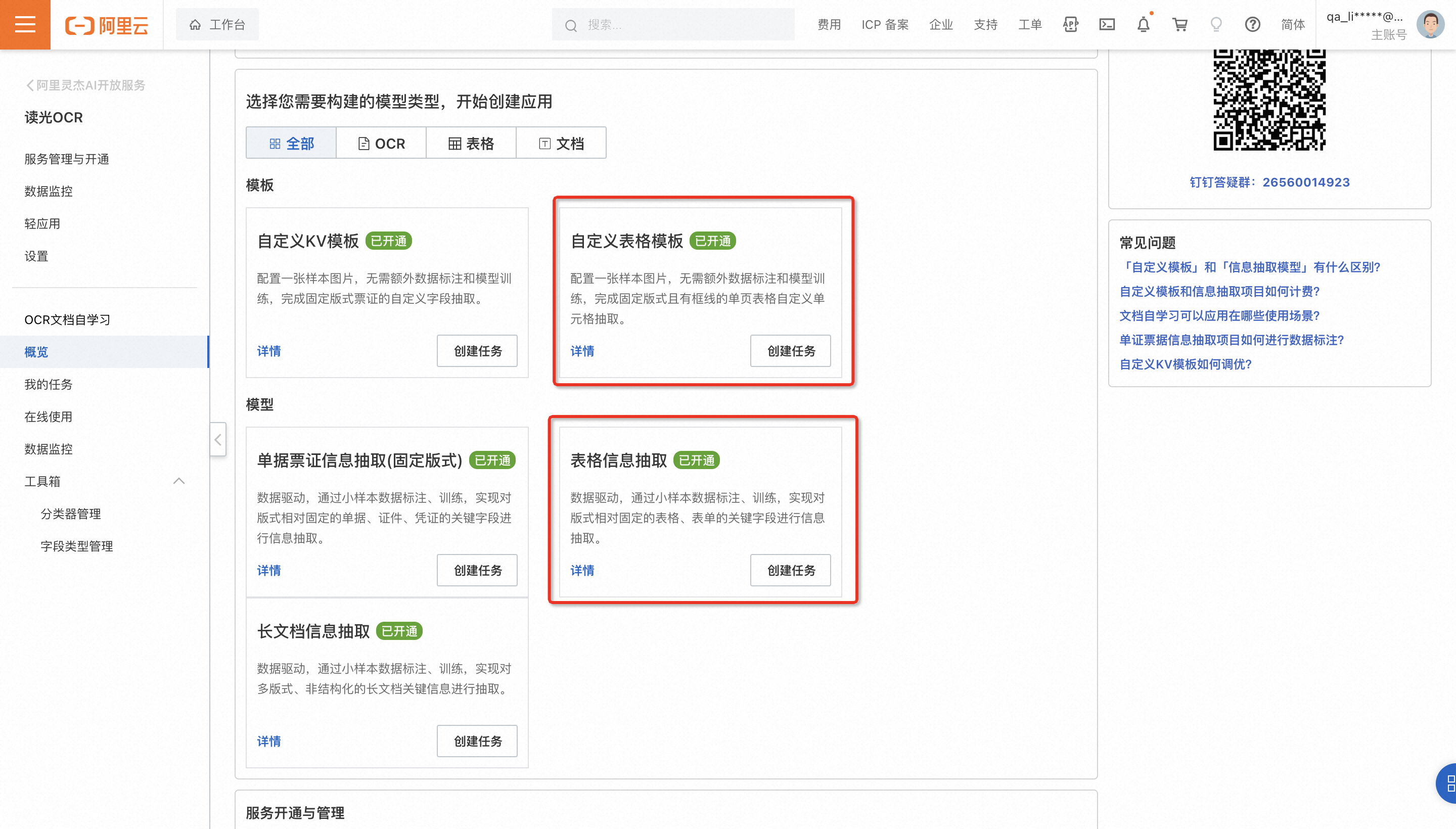
这个项目,如果是无框表格或者非固定版式表格,还是建议用表格信息抽取项目。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”


