
大佬们 Flink CDC 帮看看?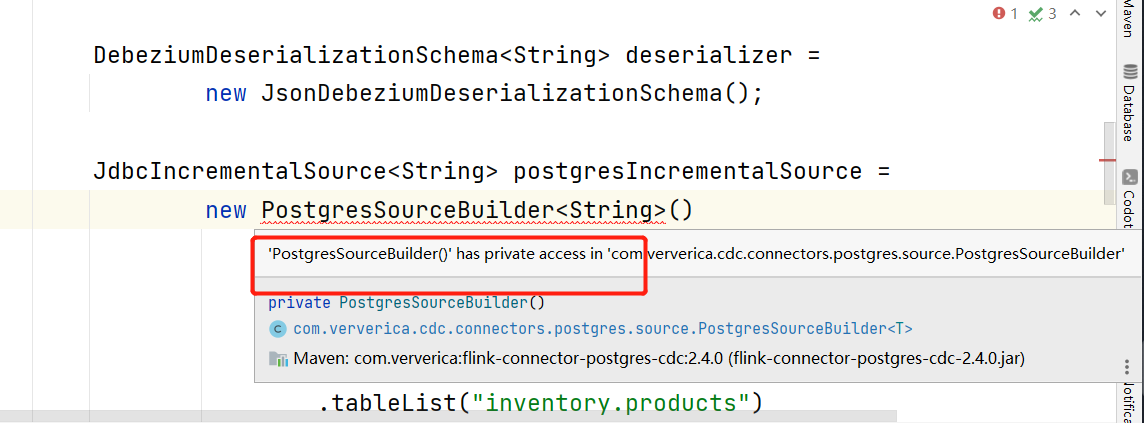
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC 是基于 Flink 流处理框架实现的一种数据同步工具,主要用于实时将数据库中的数据同步到数据湖或者数据仓库中。使用 Flink CDC 可以避免传统数据同步工具存在的数据延迟、数据丢失、数据不一致等问题,同时也可以提高数据同步的效率和性能。
下面介绍一下如何使用 Flink CDC 进行数据同步:
安装 Flink:首先需要安装 Flink,可以从官网下载 Flink 的二进制包,然后解压到指定的目录中。
安装 Flink CDC 插件:需要安装 Flink CDC 的插件,可以从 Flink CDC 的 GitHub 仓库中下载 flink-cdc-connector.jar 文件,并将其放置在 Flink 的 lib 目录中。
配置数据源:需要配置要同步的数据源,可以在 Flink CDC 的配置文件中设置数据源的连接信息、表名、列名、数据格式等信息。例如,在 MySQL 数据库中同步某个表的数据,可以使用如下的配置:
json
Copy
{
"name": "mysql-cdc",
"format": "canal-json",
"canal.server": "127.0.0.1:11111",
"canal.destination": "example",
"table-name": "test.user",
"properties.group.id": "test",
"properties.bootstrap.servers": "localhost:9092",
"scan.startup.mode": "latest-offset"
}
编写数据同步程序:需要编写 Flink 程序来实现数据同步,通常可以使用 Flink 的 Table API 或者 DataStream API 来实现。例如,使用 Table API 可以写出如下的代码:
sql_more
Copy
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE user (id INT, name STRING, age INT) WITH ('connector' = 'mysql-cdc')");
tEnv.executeSql("CREATE TABLE sink (id INT, name STRING, age INT) WITH ('connector' = 'filesystem', 'path' = '/path/to/sink', 'format' = 'csv')");
tEnv.executeSql("INSERT INTO sink SELECT id, name, age FROM user");
运行数据同步程序:最后需要将程序打包成 jar 文件,并通过 Flink 的命令行工具来执行。例如,可以使用如下的命令来执行程序:
Copy
./bin/flink run -c com.example.MyCDCJob /path/to/my-job.jar
需要注意的是,在使用 Flink CDC 进行数据同步时,需要根据实际情况进行配置和调整,以保证数据同步的性能和稳定性。同时,也需要注意保护
要在 PostgresSourceBuilder.PostgresIncrementalSource.builder() 的前面加上 image.png,您可以使用以下代码:
PostgresSource<YourDataType> source = PostgresSource.<YourDataType>builder()
// 设置 PostgreSQL 连接信息和查询语句等配置
.hostname("your_hostname")
.port(5432)
.database("your_database")
.username("your_username")
.password("your_password")
.table("your_table")
.startupMode(StartupMode.LATEST_OFFSET)
.debeziumProperties(PropertiesUtil.getDebeziumProperties())
// 其他配置项
.build(); // 构建 PostgresSource
DataStream<YourDataType> dataStream = env.addSource(source); // 将 PostgresSource 添加到数据流中
在这个示例中,您需要将 YourDataType 替换为实际的数据类型,以适应您的业务需求。还请根据实际情况填写正确的 PostgreSQL 连接信息、表名以及其他必要的配置。
使用 PostgresSourceBuilder.PostgresIncrementalSource.builder().build() 构建了一个 PostgresSource 对象,并将其作为 Flink 数据流的源(source)。这样,您就可以从 PostgreSQL 中读取数据并将其添加到 Flink 的数据流中进行后续的处理和分析。
PostgresSourceBuilder.PostgresIncrementalSource.builder()
使用这个构建,bulid前面加个 
,此回答整理自钉群“Flink CDC 社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


