
问下NLP自学习平台这个最大长度是多少?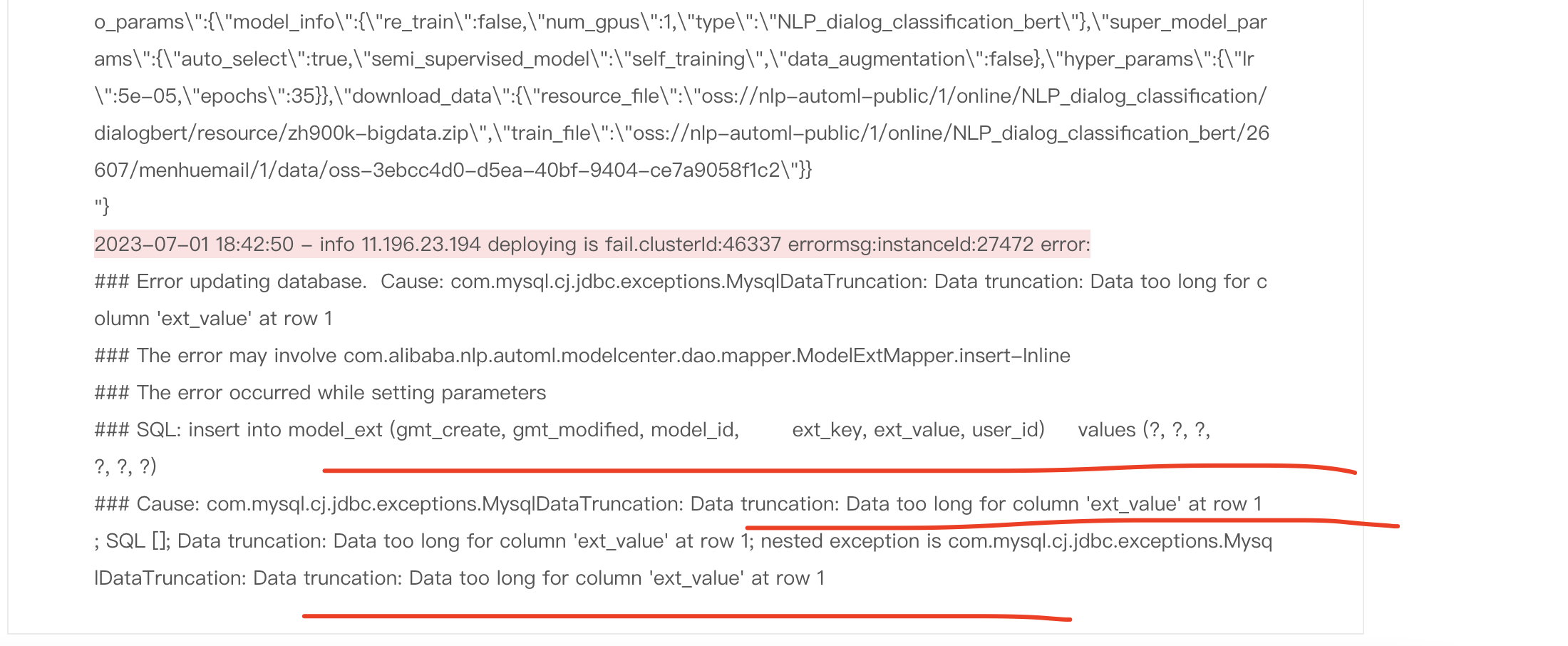 训练的时候报错了,模型类型:对话分类-高精度版(StructBERT)
训练的时候报错了,模型类型:对话分类-高精度版(StructBERT)
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
NLP自学习平台中的最大长度取决于所使用的具体模型。不同的自然语言处理模型会有不同的最大输入长度限制。
例如,对于一些基于Transformer架构的模型,如BERT、GPT-2等,通常会对输入文本的最大长度进行限制,以保证模型的性能和稳定性。一般来说,BERT模型的最大长度为512个token,GPT-2模型的最大长度为1024个token。
NLP自学习平台中的最大长度取决于所使用的模型类型和具体的限制。对于对话分类-高精度版,模型输入的最大长度为512个token。
当训练过程中出现报错时,可能是因为您的文本样本中存在超过最大长度限制的文本序列。您可以尝试以下方法来解决这个问题:
截断文本:将超过最大长度限制的文本进行截断。可以选择保留开头部分或结尾部分,以确保整体语义不受太大影响。
采样数据:如果您的训练数据集包含多个超长文本样本,可以考虑随机采样一部分样本进行训练,以保持数据集大小在可接受范围内。
缩减模型输入:根据您的应用场景和需求,可以尝试缩减模型输入的最大长度,但需要注意可能导致部分信息的丢失。
分批处理:将较长的文本拆分成多个较小的子段,在训练过程中逐个处理。
对于NLP自学习平台,最大长度的限制通常取决于所使用的模型和平台的设置。不同的模型和平台可能有不同的最大长度限制。
根据您提供的信息,您使用的是对话分类-高精度版(StructBERT)模型。对于StructBERT模型,其最大长度限制通常是512个token。超过这个限制的文本将被截断或分割成多个片段进行处理。
当您在训练过程中遇到报错时,可能是因为输入文本的长度超过了模型的最大限制。您可以尝试缩短输入文本的长度,或者考虑使用更小的模型或其他处理方式来适应模型的要求。

