
DataWorks数据集成必须用独享资源组吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,数据集成任务不一定必须使用独享资源组,可以根据实际情况选择不同的资源组。
独享资源组是一种在阿里云MaxCompute上创建的资源池,可以独享MaxCompute的计算和存储资源,提供更高的计算和处理能力。使用独享资源组可以提高数据集成任务的执行效率和性能,特别是对于数据量较大的任务,更能发挥其优势。
但是,使用独享资源组也会带来一定的成本和管理负担,因为需要为独享资源组单独购买计算和存储资源,并且需要对资源组进行管理和维护。
如果您的数据集成任务的数据量比较小,或者对任务的执行效率要求不高,可以选择使用共享资源组或者默认资源组。共享资源组可以与其他任务共享MaxCompute的计算和存储资源,成本相对较低,但是可能会受到其他任务的影响,导致任务的执行效率下降。默认资源组是MaxCompute中的一个默认资源池,不需要额外的成本和管理负担,但是也可能会受到其他任务的影响,执行效率较低。
不,DataWorks数据集成不一定必须使用独享资源组。在DataWorks中,可以选择使用共享资源组或独享资源组来运行和管理数据集成任务。
共享资源组是一种多租户环境,多个用户可以共享同一个资源组中的资源,包括存储、计算等。这种资源组适合小型项目或者资源需求较低的情况。
而独享资源组则为每个用户提供了独立的资源环境,可以单独配置和管理资源,以满足大规模、高并发的数据集成需求。这种资源组适用于对资源要求较高的项目或者需要更好的隔离性和性能的情况。
根据实际需求和预算限制,您可以选择使用共享资源组或独享资源组来支持DataWorks数据集成。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


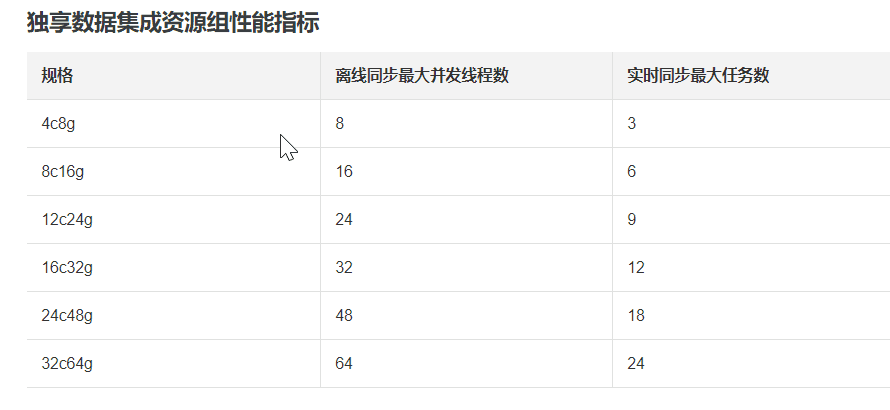
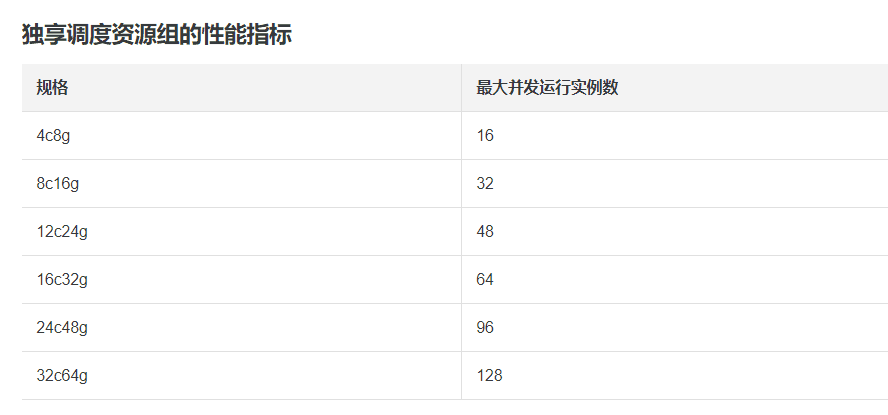 ,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”