
大佬们,Flink CDC中用kafka 的ogg-json模式,读出来怎么都是空的呢?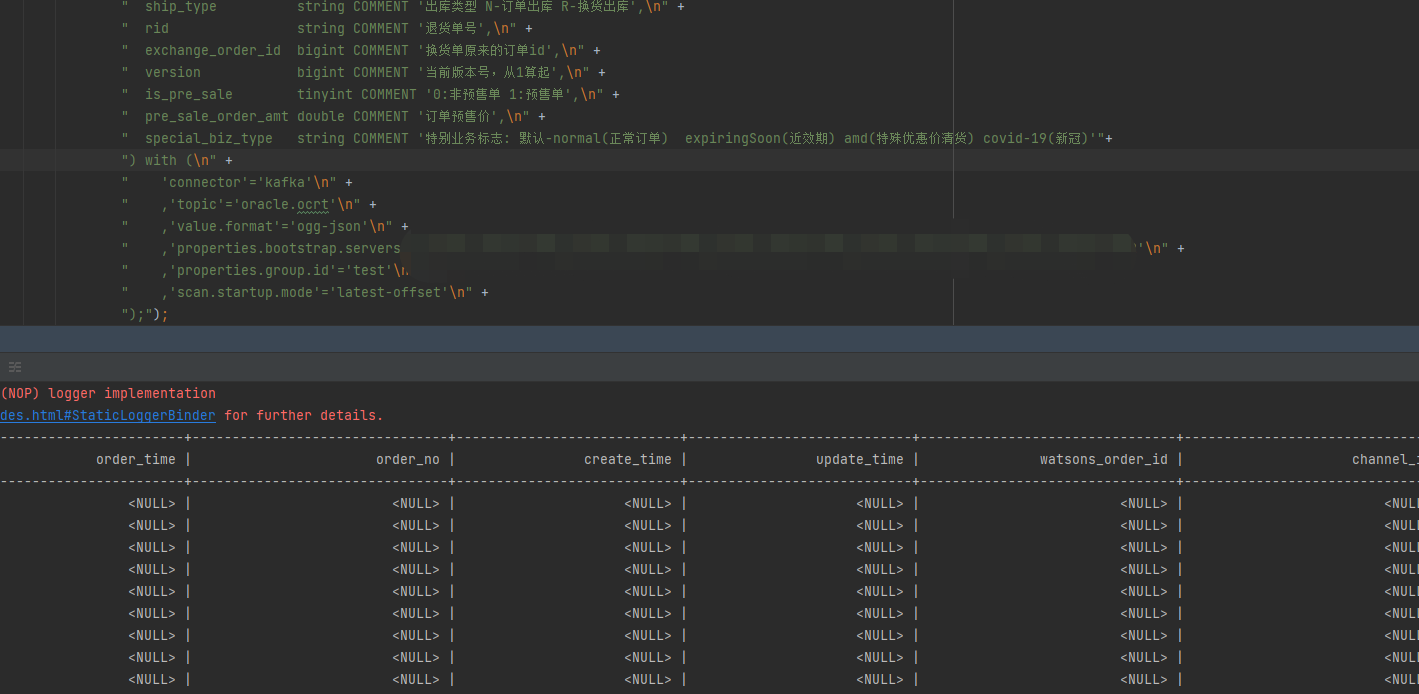
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC读取Kafka中的ogg-json格式数据时,如果读取出来的数据为空,可能是由于以下几个原因导致的。以下是详细的排查步骤和解决方案:
ogg-json是一种特定的JSON格式,通常用于Oracle GoldenGate(OGG)同步数据到Kafka。确保Kafka中存储的消息确实是ogg-json格式,并且内容符合预期。
ogg-json格式。例如:
{
"table": "schema_name.table_name",
"op_type": "I",
"op_ts": "2023-01-01T12:00:00Z",
"current_ts": "2023-01-01T12:00:01Z",
"before": null,
"after": {
"id": 1,
"name": "Alice"
}
}
如果消息内容不符合ogg-json格式,可能需要检查上游数据同步配置。
在Flink SQL中,使用ogg-json格式时,需要正确配置Kafka连接器的参数。以下是一个典型的ogg-json格式的Kafka源表DDL示例:
CREATE TABLE kafka_source (
id BIGINT,
name STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'your_topic_name',
'properties.bootstrap.servers' = 'your_kafka_broker_address',
'format' = 'ogg-json', -- 确保格式为ogg-json
'scan.startup.mode' = 'earliest-offset'
);
关键点:format参数
确保format参数设置为ogg-json,否则Flink无法正确解析消息内容。
检查其他参数
确认properties.bootstrap.servers和topic等参数配置正确,避免因网络或Topic名称错误导致无法读取数据。
ogg-json格式的消息通常包含before、after等字段,表示变更前后的数据。如果直接读取after字段为空,可能是因为: - 数据本身没有变更(即after字段为空)。 - Flink SQL未正确映射字段。
解决方案: - 在DDL中明确指定字段映射关系。例如:
CREATE TABLE kafka_source (
id BIGINT,
name STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'your_topic_name',
'properties.bootstrap.servers' = 'your_kafka_broker_address',
'format' = 'ogg-json',
'scan.startup.mode' = 'earliest-offset',
'ogg-json.ignore-parse-errors' = 'true' -- 忽略解析错误
);
ogg-json.ignore-parse-errors参数跳过这些消息,避免作业失败。如果使用了Kafka JSON Catalog自动推导Schema,可能会因为消息内容不一致导致推导失败。建议手动定义Schema以确保字段类型和结构正确。
CREATE TABLE kafka_source (
id BIGINT,
name STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'your_topic_name',
'properties.bootstrap.servers' = 'your_kafka_broker_address',
'format' = 'ogg-json',
'scan.startup.mode' = 'earliest-offset'
);
ogg-json格式中的时间戳字段(如op_ts)可能需要特殊处理。如果时间戳格式不匹配,可能导致解析失败。
json.timestamp-format.standard参数指定时间戳格式。例如:
'json.timestamp-format.standard' = 'ISO-8601'
即使Flink和Kafka之间的网络是连通的,也可能因为Kafka Broker返回的Endpoint信息不正确导致无法读取数据。
zkCli.sh
ls /brokers/ids
get /brokers/ids/{your_broker_id}
确认listener_security_protocol_map中的Endpoint是否可以被Flink访问。
如果Kafka的某个分区没有数据,或者数据存在乱序,可能导致Flink无法正确读取数据。
检查分区数据分布
使用Kafka命令行工具查看每个分区的数据分布情况:
kafka-consumer-groups.sh --bootstrap-server your_kafka_broker_address --describe --group your_group_id
调整并发数
如果作业并发数大于Kafka Topic的分区数,可能导致部分并发无数据流入。建议将作业并发数设置为小于或等于分区数。
通过以上步骤,您可以逐步排查并解决Flink CDC读取Kafka ogg-json格式数据为空的问题。重点检查以下几点: 1. Kafka消息格式是否正确。 2. Flink SQL中的Connector配置是否准确。 3. 字段映射和Schema定义是否合理。 4. 时间戳格式是否匹配。 5. 网络连通性和分区数据分布是否正常。
如果问题仍未解决,请提供更多上下文信息(如Kafka消息样例、Flink SQL配置等),以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

