
DataWorks分区表存储都没变怎么办?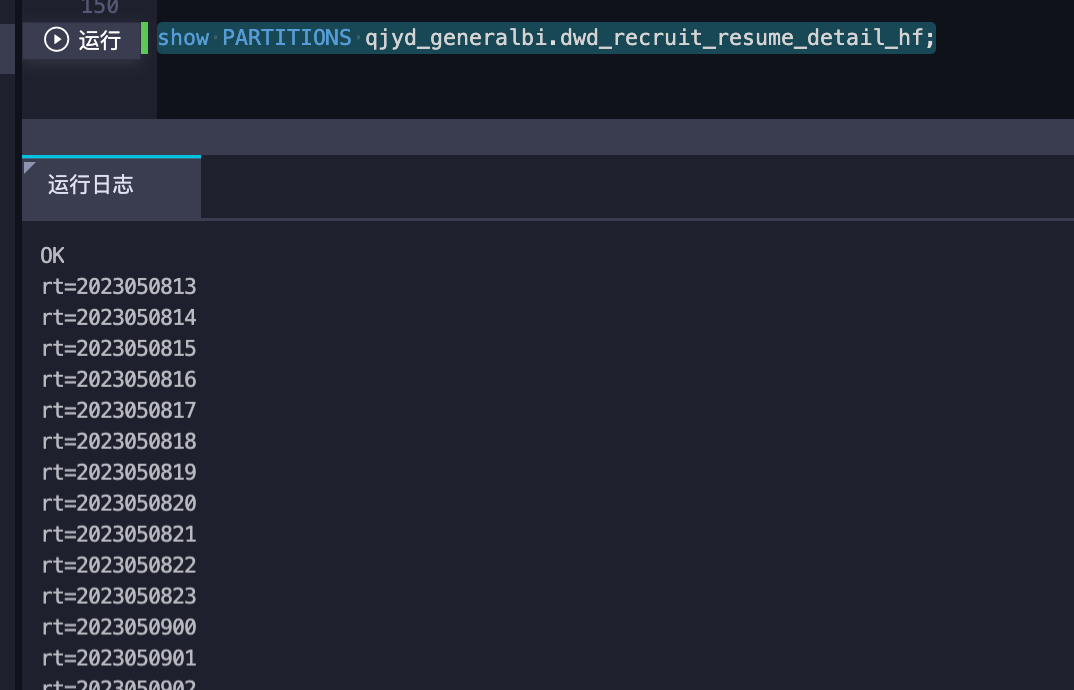
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用DataWorks时,如果发现分区表的存储量没有变化,可能是由于以下几个原因导致的。以下是详细的分析和解决方法:
DataWorks的数据总览页面中的存储量统计是离线计算的,存在T+1的延迟。这意味着即使您删除了部分数据或调整了分区,存储量的变化可能不会立即反映在界面上。
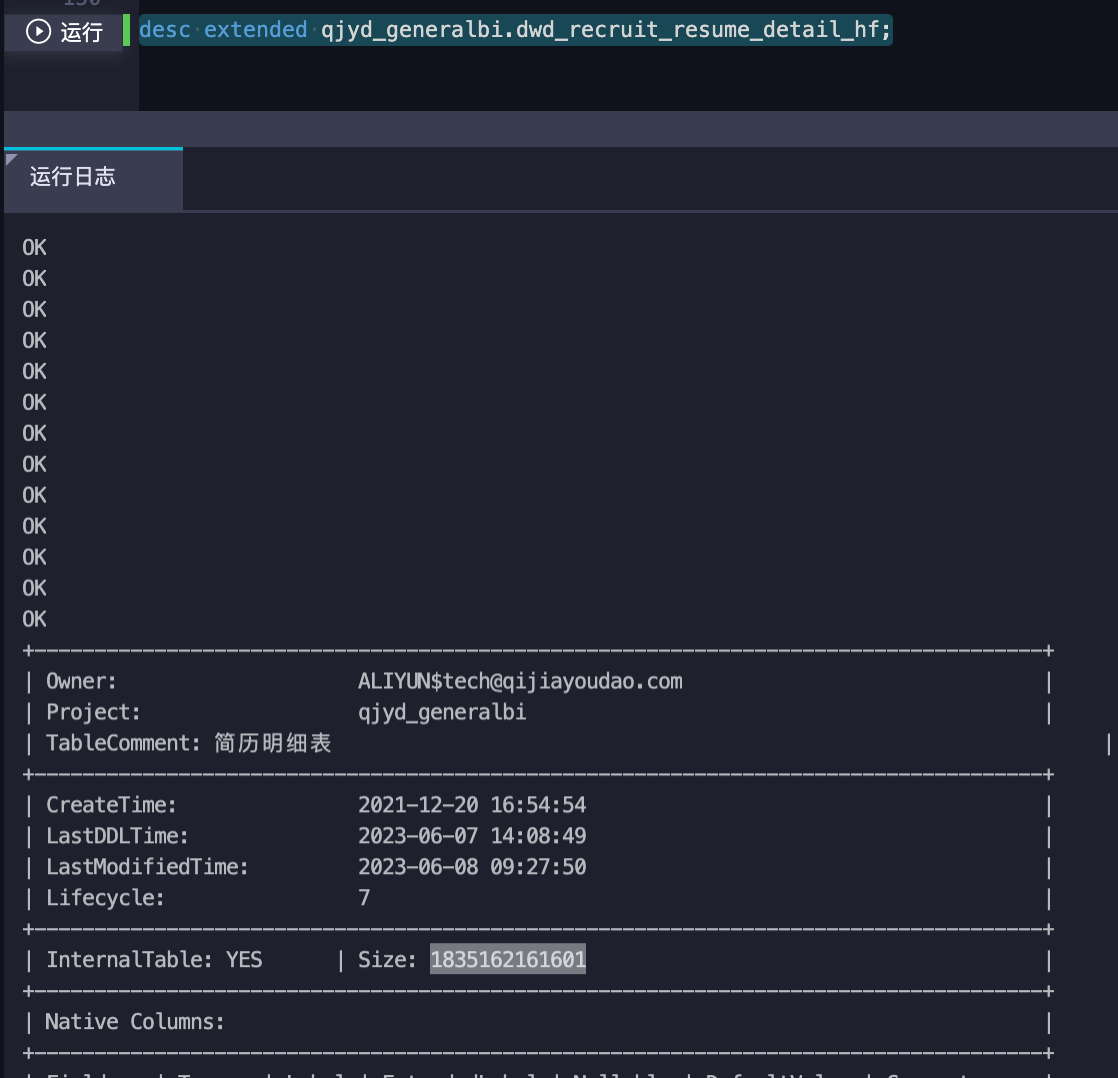
DESC TABLE命令直接查询表的物理存储大小:
DESC TABLE your_table_name;
如果分区表的某些分区未被正确删除,可能导致存储量未减少。例如,手动删除分区时可能存在遗漏,或者生命周期设置未生效。
SHOW PARTITIONS your_table_name;
如果发现仍有不需要的分区,可以手动删除:
ALTER TABLE your_table_name DROP PARTITION (partition_spec);
ALTER TABLE your_table_name SET LIFECYCLE days;
注意:生命周期到期后,分区表会删除分区,非分区表会直接删除表。
在数据同步任务中,如果写入策略配置不当,可能导致数据重复写入或覆盖失败,从而影响存储量的变化。
uploader map size has reached uploaderMapMaximumSize
如果出现该问题,建议优化Flush间隔或减少分区列的枚举值个数。
在数据同步过程中,如果存在脏数据或数据质量问题,可能导致目标表的数据未能正确更新。
bizdate)正确替换。例如:
WHERE pt = ${bizdate}
如果参数未正确替换,可能导致数据未按预期写入。
即使数据已被删除,底层存储空间可能未及时释放。这通常与MaxCompute的存储机制有关。
ALTER TABLE your_table_name TOUCH;
该命令会强制刷新表的元数据,释放未使用的存储空间。
如果分区表的设计不合理,可能导致存储浪费。例如,使用拉链存储时,新增的时间戳字段(如start_dt和end_dt)会显著增加存储开销。
DESC TABLE命令查看实际存储量。通过以上步骤,您可以有效排查并解决DataWorks分区表存储量未变化的问题。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

