
您好,机器翻译中翻译完后多了个br标签,怎么处理?
 { "lang_origin": "auto", "lang_target": "en", "txt_origin": "
{ "lang_origin": "auto", "lang_target": "en", "txt_origin": "
测试的
\n<a title="课程成绩 (1).xlsx" href="http://ibodao-test.obs.cn-east-3.myhuaweicloud.com/uploads/2022/05-25/628da492b45d8.xlsx" target="_blank" rel="noopener" download="课程成绩 (1).xlsx">课程成绩 (1).xlsx
\n<a title="测试的课件互动.pptx" href="http://ibodao-test.obs.cn-east-3.myhuaweicloud.com/uploads/2021/11-22/619b3b9fd39f2.pptx">测试的课件互动.pptx
\n<video controls="controls" width="300" height="150">\n<source src="http://ibodao-test.obs.cn-east-3.myhuaweicloud.com/uploads/2023/06-01/64784ec6089d0.mp4" type="video/mp4" />
" } 内部系统没有记录requestid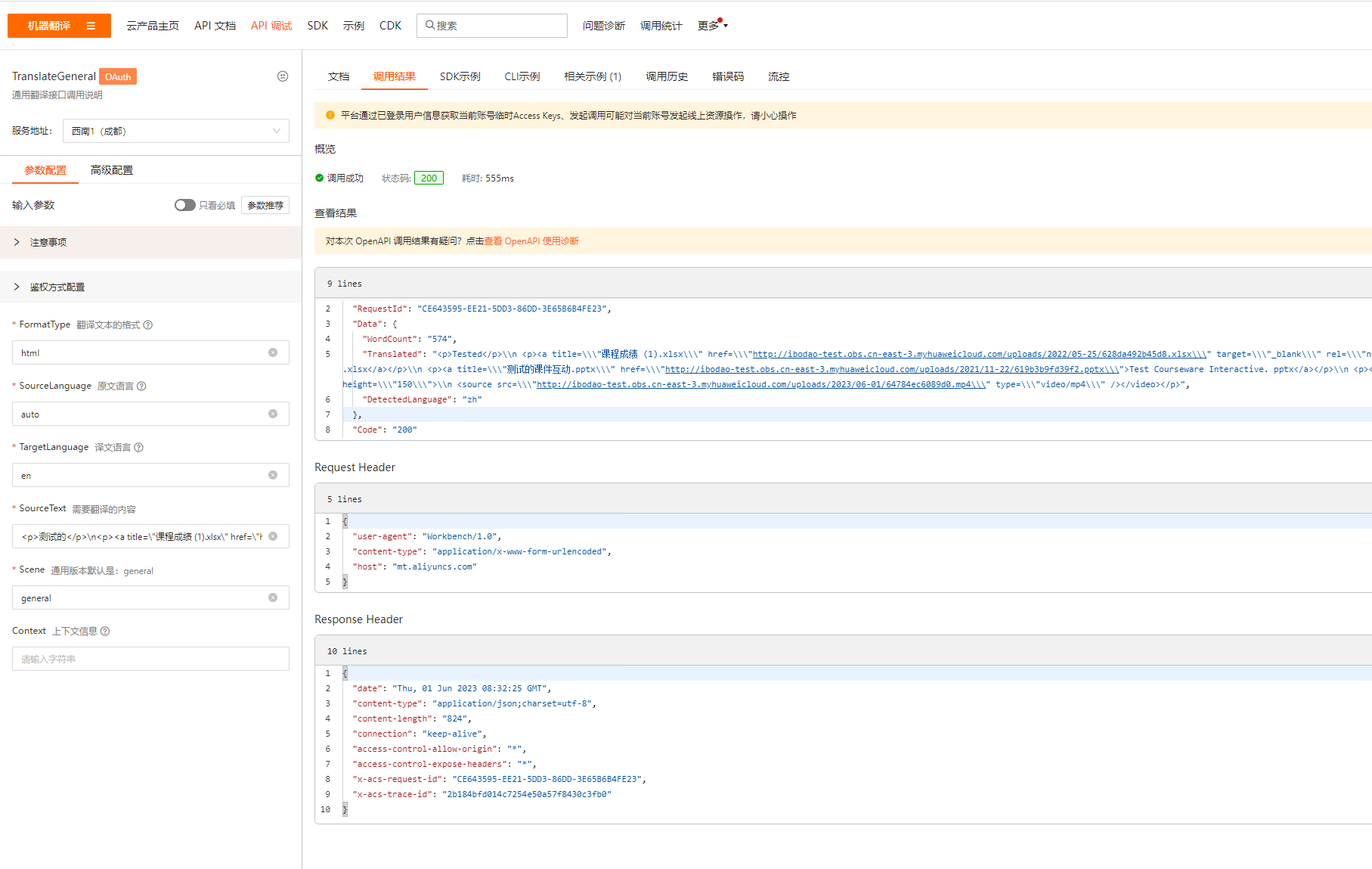 在这调试,好像又正常
在这调试,好像又正常
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
机器翻译中出现多余的
标签可能是由于原文中存在换行符\n,而机器翻译工具将其翻译成了
标签。如果您不希望在翻译结果中出现
标签,可以考虑在翻译前将原文中的换行符去掉,然后再进行翻译。
在给出具体的解决方案之前,需要进一步了解您的机器翻译系统以及您的代码实现情况。如果您是使用第三方机器翻译API进行翻译,可以查看该API的文档,了解其是否提供了相应的参数或选项,以控制输出结果中是否包含
标签。如果您是自己实现机器翻译系统,可以修改代码中的相关逻辑,以去除原文中的换行符。
此外,如果您在机器翻译后的文本中发现多余的
标签,可以使用字符串处理函数进行去除,例如Python中的replace()函数可以将文本中的
标签替换为空字符串。
关于您提到的调试问题,如果在调试时没有出现多余的
标签,可能是由于您的调试环境和实际部署环境不同,或者是由于机器翻译系统在不同的上下文中表现不同。为了

