
seata xa事务这两个地方能不能改一下?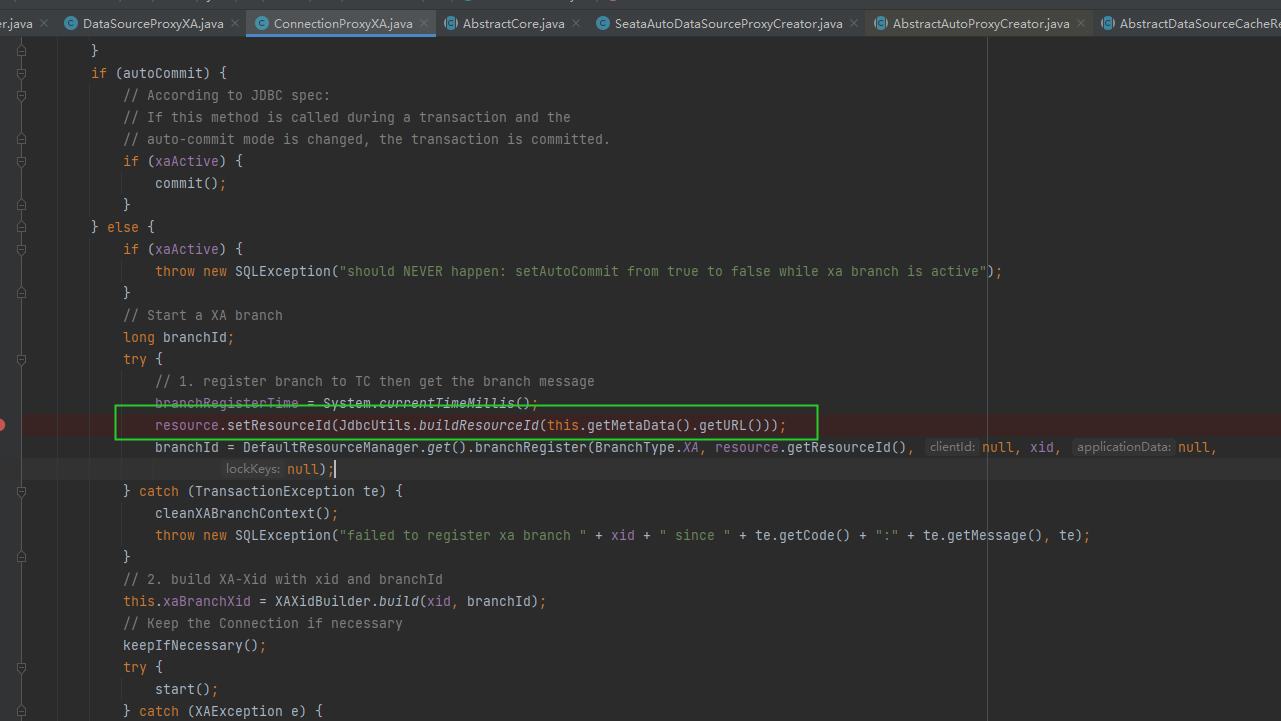
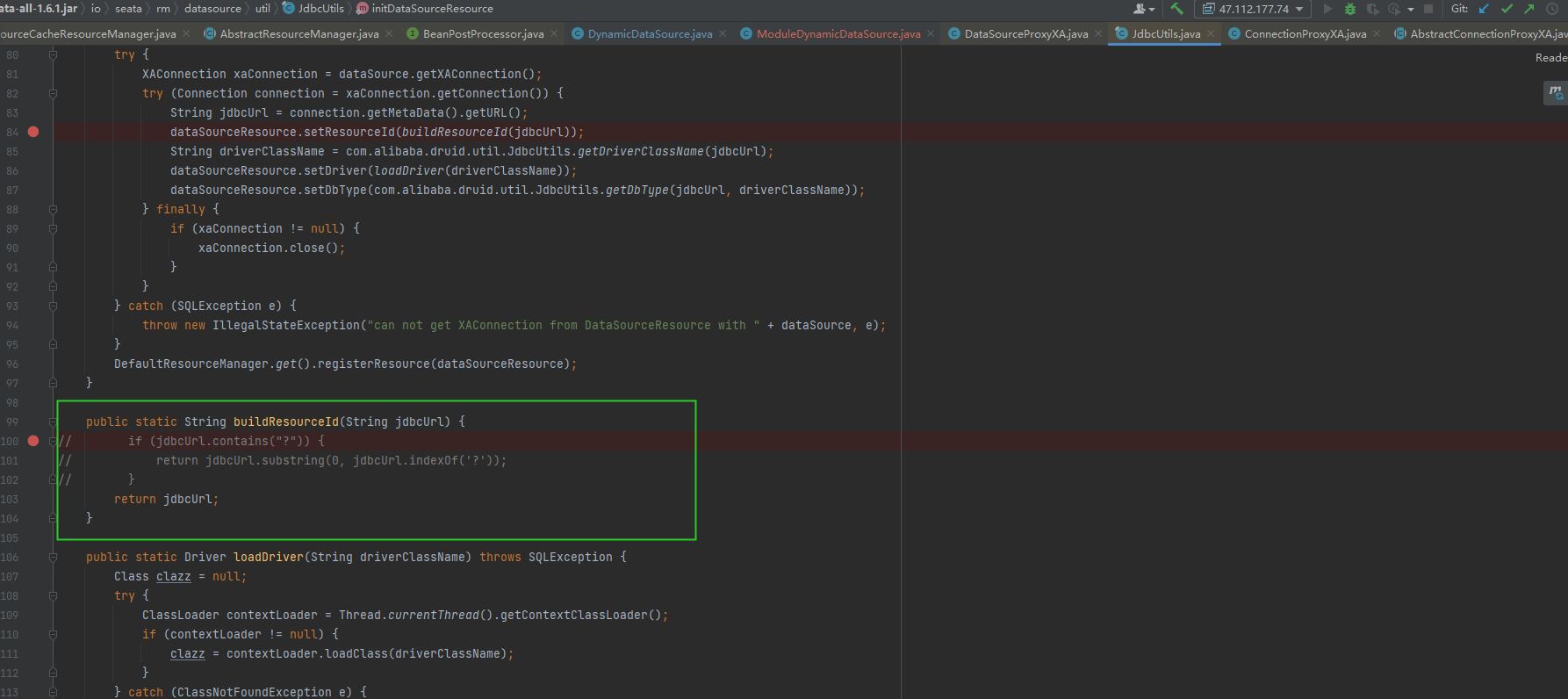 因为我们的jdbc url是类似这种的 <1>jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena&TimeZone=Atlantic/St_Helena <2>jdbc:postgresql://xxxxxxx:5432/device?currentSchema=abc&TimeZone=Atlantic/St_Helena 如果resource id只截取到问号前jdbc:postgresql://xxxxxxx:5432/device,就区分不了不同的数据源
因为我们的jdbc url是类似这种的 <1>jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena&TimeZone=Atlantic/St_Helena <2>jdbc:postgresql://xxxxxxx:5432/device?currentSchema=abc&TimeZone=Atlantic/St_Helena 如果resource id只截取到问号前jdbc:postgresql://xxxxxxx:5432/device,就区分不了不同的数据源
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,看了你的描述,对于阿里云Seata的XA事务,resource id不支持直接修改,因为resource id是通过解析JDBC URL来生成的,而且目前的实现方式是将JDBC URL的前缀部分作为resource id。
针对你说的这种情况,需要你将不同的数据源区分开来,可以修改Seata源码,自定义生成resource id的逻辑。
或者使用Seata的动态数据源支持,即使用Seata提供的DataSourceProxy连接池,通过拦截和代理JDBC连接来实现分库分表和动态数据源的切换。
在你的情况下,由于jdbc url中的resource id只截取到问号前的部分,无法区分不同的数据源。这将导致Seata无法正确识别和管理不同的数据源。
为了解决这个问题,你可以将jdbc url中的currentSchema的值作为resource id的一部分,以便区分不同的数据源。
以下是一个示例的registry.conf文件内容:
registry {
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
}
}
config {
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
dataId = "file.conf"
}
}
store {
mode = "db"
db {
dataSource = "db1"
dbType = "postgresql"
driverClassName = "org.postgresql.Driver"
url = "jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena&TimeZone=Atlantic/St_Helena"
user = "your_username"
password = "your_password"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
}
}
在这个示例中,dataSource被设置为db1,而在Seata的db.conf文件中,你可以根据不同的dataSource配置不同的数据库信息。这样,Seata就能理解不同的数据源,并将事务信息存储到不同的数据库表中。
同时,你需要确保在Seata的db.conf文件中,为每个数据源定义正确的数据库连接信息,并在Seata的server端配置文件中正确引用这些数据源。
通过按照上述方法,你可以在Seata中区分不同的数据源,并将事务信息正确地保存到相应的数据源中。
在 Seata XA 事务管理中,资源 ID(Resource ID)是用来唯一标识一个资源实例(比如数据库数据源)的。通常,资源 ID 是根据 JDBC URL 生成的。如果你的应用程序中有多个具有相同前缀但不同参数的 JDBC URL,仅仅使用问号?之前的部分作为资源 ID 确实会导致它们无法被区分开。
作为临时解决方案,如果可能的话,你可以尝试使用不同的数据库实例或者不同的端口来区分不同的数据源。这个方法可能需要在数据库层面上进行一些调整。
解决这个问题的一个方法是在buildResourceId方法中,除了截取URL到问号之前的部分,还应该包含URL中的schema信息。例如:
java
public static String buildResourceId(String jdbcUrl) {
if (jdbcUrl.contains("?")) {
int index = jdbcUrl.indexOf('?');
return jdbcUrl.substring(0, index) + "?" + jdbcUrl.substring(index + 1).split("&")[0];
}
return jdbcUrl;
}
这样,对于你给出的两个示例URL,生成的resourceId就会分别是:
jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena
jdbc:postgresql://xxxxxxx:5432/device?currentSchema=abc
这样就可以根据resourceId来区分不同的数据源了。
请注意,这个修改可能需要在Seata的源代码中进行,并重新编译Seata。如果你不希望修改Seata的源代码,也可以考虑通过其他方式来设置和获取resourceId,例如在你的应用代码中添加一个额外的映射表,将JDBC URL映射到自定义的resourceId。
public class CustomDataSourceKey implements DataSourceKey {
private final String url;
public CustomDataSourceKey(String url) {
this.url = url;
}
@Override
public String getKey() {
// 在这里根据您的需求截取 URL 的相应部分作为 key
String[] parts = url.split("&");
StringBuilder key = new StringBuilder();
for (String part : parts) {
if (part.startsWith("currentSchema")) {
key.append(part.substring("currentSchema".length() + 1));
}
}
return key.toString();
}
}
DataSource dataSource = DataSourceBuilder.create()
.url("jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena&TimeZone=Atlantic/St_Helena")
.key(new CustomDataSourceKey("jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena&TimeZone=Atlantic/St_Helena"))
.build();
在 Seata 中,为了区分不同的 DataSource,您需要为每个 DataSource 创建一个唯一的 DataSourceKey。在您提供的代码中,您已经创建了一个 CustomDataSourceKey 类,该类根据 jdbc URL 来构建 key。这是一个很好的解决方案,因为它允许您根据 URL 的不同部分来区分不同的 DataSource。
以下是对您提供的代码的详细解释:
public class CustomDataSourceKey implements DataSourceKey {
private final String url;
public CustomDataSourceKey(String url) {
this.url = url;
}
@Override
public String getKey() {
// 在这里根据您的需求截取 URL 的相应部分作为 key
String[] parts = url.split("&");
StringBuilder key = new StringBuilder();
for (String part : parts) {
if (part.startsWith("currentSchema")) {
key.append(part.substring("currentSchema".length() + 1));
}
}
return key.toString();
}
}
CopyCopy
DataSource dataSource = DataSourceBuilder.create()
.url("jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena&TimeZone=Atlantic/St_Helena")
.key(new CustomDataSourceKey("jdbc:postgresql://xxxxxxx:5432/device?currentSchema=st_helena&TimeZone=Atlantic/St_Helena"))
.build();
CopyCopy
通过这种方式,您可以为具有相同 URL 但不同 currentSchema 的 DataSource 创建唯一的 key。这样,Seata 就可以根据这些 key 来正确地区分不同的 DataSource。
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。

