
DataWorks实现自动解析的实现原理是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
自动解析:通过代码自动解析调度依赖关系。自动解析的实现原理:代码中只能拿到表名,自动解析功能可以根据表名解析出对应的产出任务。类型节点代码如下所示。INSERT OVERWRITE TABLE pm_table_a SELECT * FROM project_b_name.pm_table_b ;解析出来的依赖关系如下。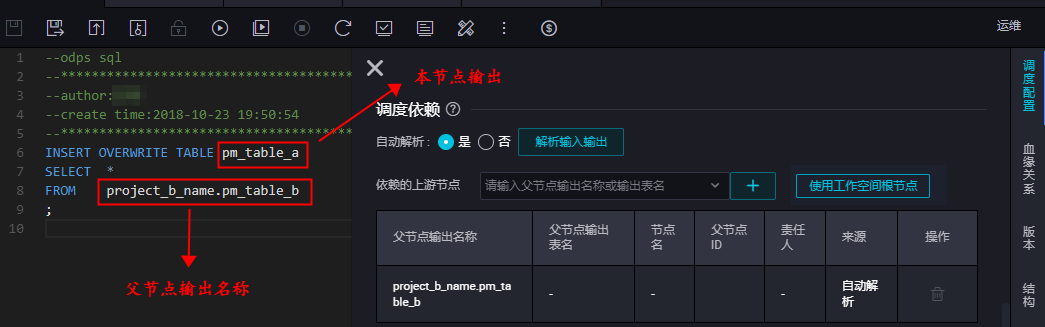 DataWorks会自动解析本节点,即依赖project_b_name产出 pm_table_b的节点,同时本节点最终产出 pm_table_a ,因此父节点输出名称为 project_b_name.pm_table_b,本节点的输出名称为 project_name.pm_table_a(本工作空间名称为test_pm_01)。如果您不想使用从代码解析到的依赖,则选择否。如果代码中有很多表是临时表:如t_开头的表为临时表。则该表不会被解析为调度依赖。可以通过项目配置,定义以什么形式开头的表为临时表。如果代码中的一个表,既是产出表又是被引用表(被依赖表),则解析时只解析为产出表。如果代码中的一个表,被多次引用或者被多次产出,则解析时只解析一个调度依赖关系。说明 默认情况下,表名为t_开头的会被当成临时表,自动解析不解析临时表。如果t_开头不是临时表,请联系自己的项目管理员到工作空间配置页面进行修改。
DataWorks会自动解析本节点,即依赖project_b_name产出 pm_table_b的节点,同时本节点最终产出 pm_table_a ,因此父节点输出名称为 project_b_name.pm_table_b,本节点的输出名称为 project_name.pm_table_a(本工作空间名称为test_pm_01)。如果您不想使用从代码解析到的依赖,则选择否。如果代码中有很多表是临时表:如t_开头的表为临时表。则该表不会被解析为调度依赖。可以通过项目配置,定义以什么形式开头的表为临时表。如果代码中的一个表,既是产出表又是被引用表(被依赖表),则解析时只解析为产出表。如果代码中的一个表,被多次引用或者被多次产出,则解析时只解析一个调度依赖关系。说明 默认情况下,表名为t_开头的会被当成临时表,自动解析不解析临时表。如果t_开头不是临时表,请联系自己的项目管理员到工作空间配置页面进行修改。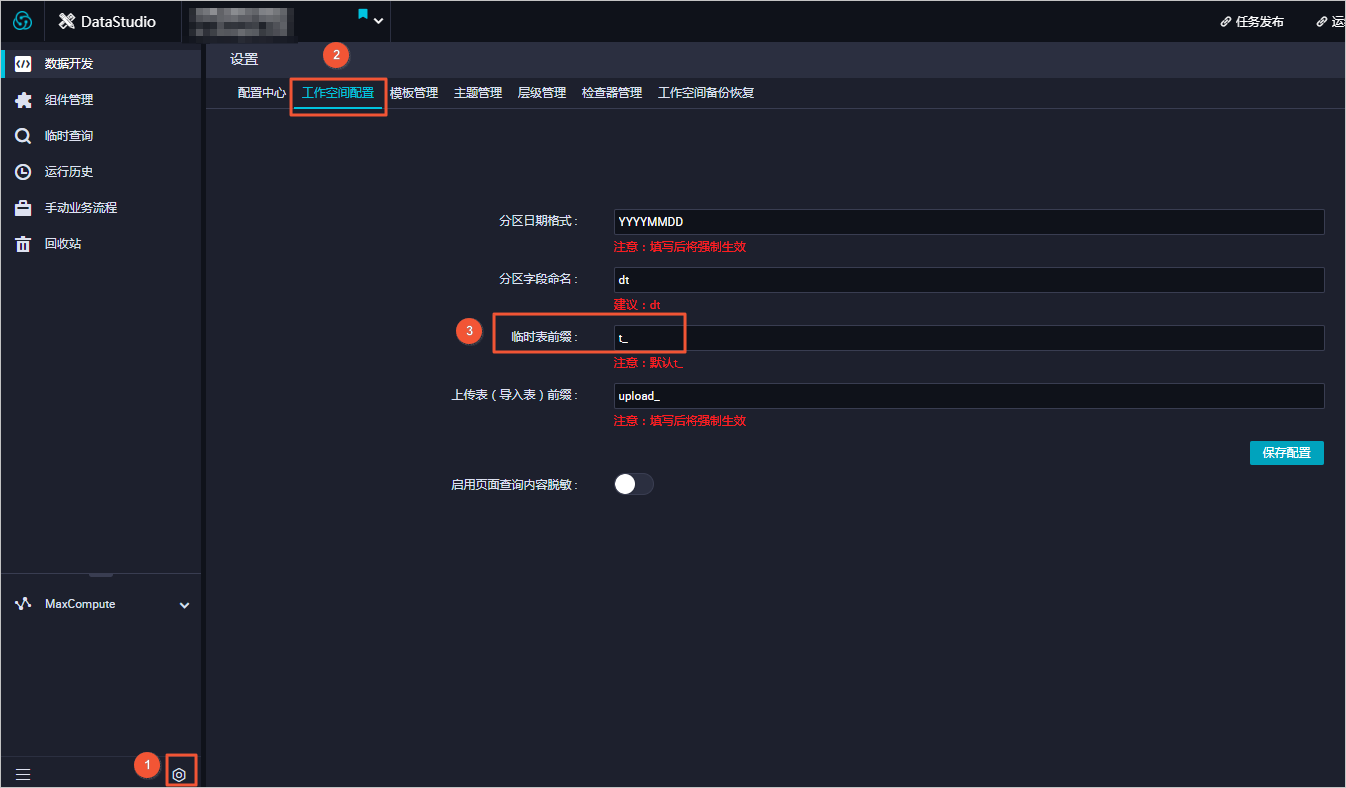
https://help.aliyun.com/document_detail/94780.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

