
问题描述 RocketMQ从节点频繁CPU sys飙高,很多次从节点直接挂掉了。
详情截图如下:
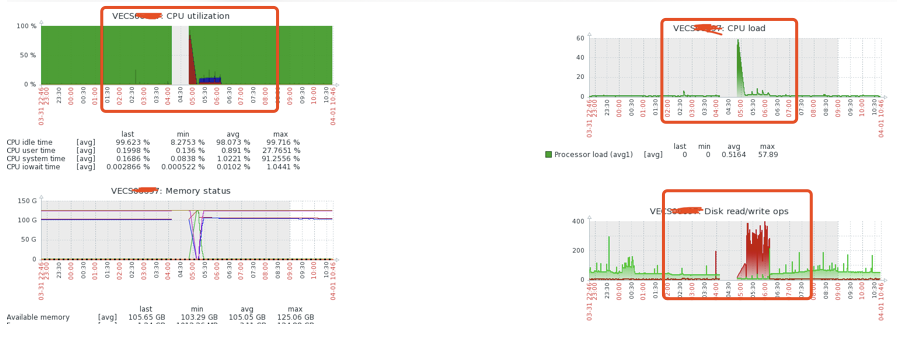
集群情况
RocketMQ版本使用4.5.2,4主4从模式 集群tps在8000左右 单节点配置32C/128G/1.7T 其中2从部署在阿里云ECS上,即一个集群6台ECS 内核版本:Linux version 2.6.32-754.18.2.el6.x86_64 (mockbuild@x86-01.bsys.centos.org) (gcc version 4.4.7 20120313 (Red Hat 4.4.7-23) (GCC) ) #1 SMP Wed Aug 14 16:26:59 UTC 2019
内核参数
vm.overcommit_memory=1 vm.drop_caches=1 vm.zone_reclaim_mode=0 vm.max_map_count=655360 vm.dirty_background_ratio=50 vm.dirty_ratio=50 vm.dirty_writeback_centisecs=360000 vm.page-cluster=3 vm.swappiness=1
备注:搭建时的内核参数主从一致的,内容如上,之前使用该参数配置在RocketMQ集群4.1版本中,未发生任何异常情况。
从节点JVM参数
/usr/java/jdk1.8.0_66/bin/java -server -Xms8g -Xmx8g -Xmn4g -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:SoftRefLRUPolicyMSPerMB=0 -verbose:gc -Xloggc:/dev/shm/rmq_broker_gc_%p_%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintAdaptiveSizePolicy -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m -XX:-OmitStackTraceInFastThrow -XX:+AlwaysPreTouch -XX:MaxDirectMemorySize=15g -XX:-UseLargePages -XX:-UseBiasedLocking -Djava.ext.dirs=/usr/java/jdk1.8.0_66/jre/lib/ext:/workspace/rocketmq-all-4.5.2-bin-release/bin/../lib -cp .:/workspace/rocketmq-all-4.5.2-bin-release/bin/../conf:.:/usr/java/jdk1.8.0_66/lib/tools.jar:/usr/java/jdk1.8.0_66/lib/dt.jar org.apache.rocketmq.broker.BrokerStartup -c /workspace/rocketmq-all-4.5.2-bin-release/conf/2m-2s-async/broker-d-s.properties
备注:堆内存分配为8G
问题详情 主节点出现闪断 在3月16日出现了CPU sys飙高导致broker约有1分钟的不可用,具体系统日志错误为
2020-03-16T17:56:07.505715+08:00 VECS0xxxx kernel: [] ? __alloc_pages_nodemask+0x7e1/0x960 2020-03-16T17:56:07.505717+08:00 VECS0xxxx kernel: java: page allocation failure. order:0, mode:0x20 2020-03-16T17:56:07.505719+08:00 VECS0xxxx kernel: Pid: 12845, comm: java Not tainted 2.6.32-754.17.1.el6.x86_64 #1 2020-03-16T17:56:07.505721+08:00 VECS0xxxx kernel: Call Trace: 2020-03-16T17:56:07.505724+08:00 VECS0xxxx kernel: [] ? __alloc_pages_nodemask+0x7e1/0x960 2020-03-16T17:56:07.505726+08:00 VECS0xxxx kernel: [] ? dev_queue_xmit+0xd0/0x360 2020-03-16T17:56:07.505729+08:00 VECS0xxxx kernel: [] ? ip_finish_output+0x192/0x380 2020-03-16T17:56:07.505732+08:00 VECS0xxxx kernel: [] ?
截图如下:
解决方式调整了主节点的内核参数
vm.zone_reclaim_mode = 1
vm.min_free_kbytes = 512000
当前主节点的内核参数配置为
vm.overcommit_memory=1 vm.drop_caches=1 vm.zone_reclaim_mode=0 vm.max_map_count=655360 vm.dirty_background_ratio=25 vm.dirty_ratio=25 vm.dirty_writeback_centisecs=360000 vm.page-cluster=3 vm.swappiness=1 vm.zone_reclaim_mode = 1 vm.min_free_kbytes = 512000
备注:主节点详细过程参见下文:RocketMQ关于Broker闪断故障排查【实战笔记】 https://mp.weixin.qq.com/s/8EE7_MqV-oZBYqtrdrlUIw
从节点挂掉情况 调整主节点时把从节点也统一调整了,从节点也调整成了zone_reclaim_mode和min_free_kbytes参数
vm.overcommit_memory=0 vm.drop_caches=1 vm.zone_reclaim_mode=0 vm.max_map_count=655360 vm.dirty_background_ratio=10 vm.dirty_ratio=10 vm.dirty_writeback_centisecs=360000 vm.page-cluster=3 vm.swappiness=1
vm.zone_reclaim_mode = 1 vm.min_free_kbytes = 512000
此后从节点频繁出现了CPU飙高导致节点挂掉的情况,都是CPU sys在飙高,系统日志如下
30 2020-03-27T10:35:28.769900+08:00 VECSxxxx kernel: INFO: task AliYunDunUpdate:29054 blocked for more than 120 seconds. 31 2020-03-27T10:35:28.769932+08:00 VECSxxxx kernel: Not tainted 2.6.32-754.17.1.el6.x86_64 #1 32 2020-03-27T10:35:28.771650+08:00 VECS0xxxx kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. 33 2020-03-27T10:35:28.774631+08:00 VECS0xxxx kernel: AliYunDunUpda D ffffffff815592fb 0 29054 1 0x10000080 34 2020-03-27T10:35:28.777500+08:00 VECS0xxxx kernel: ffff8803ef75baa0 0000000000000082 ffff8803ef75ba68 ffff8803ef75ba64 35 2020-03-27T10:35:28.780557+08:00 VECS0xxxx kernel: ffff8803ef75bae8 00000000000014a6 002d61b26118849c ffff880099b18c00 36 2020-03-27T10:35:28.782853+08:00 VECS0xxxx kernel: 00000003f95c0502 0000000000000a2a ffff880488c665f8 ffff8803ef75bfd8
为解决“blocked for more than 120 seconds”问题两次调整从节点dirty参数,从50%调整到25%后还是出现飙高情况,然后调整到10%,最终还是出现CPU飙高,截图如下:
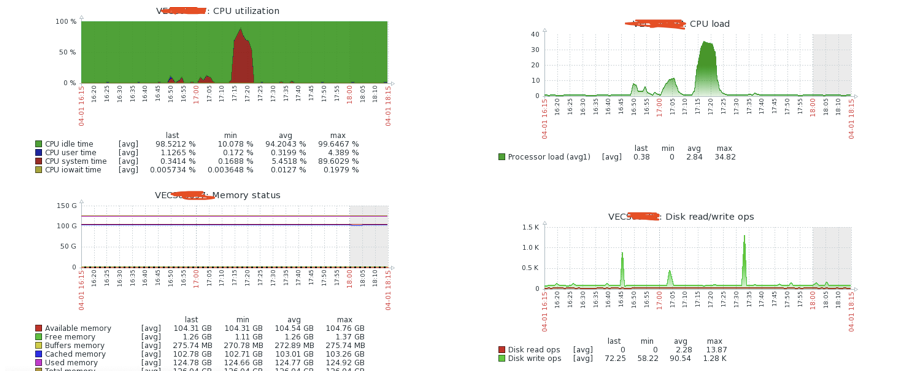
系统message日志
1656 2020-04-01T17:19:52.462310+08:00 VECS0xxxx kernel: INFO: task netstat:30311 blocked for more than 120 seconds. 1657 2020-04-01T17:19:52.464266+08:00 VECS0xxx kernel: Not tainted 2.6.32-754.18.2.el6.x86_64 #1 1658 2020-04-01T17:19:52.466011+08:00 VECS0xxxx kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this messa ge. 1659 2020-04-01T17:19:52.468971+08:00 VECS0xxxx kernel: netstat D ffffffff8160d9e0 0 30311 1 0x10000084 1660 2020-04-01T17:19:52.471907+08:00 VECS0xxx kernel: ffff8801b0443d10 0000000000000082 0000000000000000 ffff88011ffc6ab0 1661 2020-04-01T17:19:52.474211+08:00 VECS0xxxx kernel: ffff88000005b5c0 ffff88011ffc6ab0 0000275feaea8627 0000000000000002 1662 2020-04-01T17:19:52.477311+08:00 VECS0xxxx kernel: 00000001029004e5 000000000000030f ffff88011ffc7068 ffff8801b0443fd8 1663 2020-04-01T17:19:52.477323+08:00 VECS0xxxx kernel: Call Trace: 1664 2020-04-01T17:19:52.478328+08:00 VECS0xxxx kernel: [] ? mntput_no_expire+0x30/0x110 1665 2020-04-01T17:19:52.482136+08:00 VECS0xxxx kernel: [] rwsem_down_failed_common+0x95/0x1d0 1666 2020-04-01T17:19:52.482149+08:00 VECS0xxxx kernel: [] ? security_inode_permission+0x25/0x30 1667 2020-04-01T17:19:52.484150+08:00 VECS0xxxx kernel: [] rwsem_down_read_failed+0x26/0x30 1668 2020-04-01T17:19:52.487981+08:00 VECS0xxxx kernel: [] call_rwsem_down_read_failed+0x14/0x30 1669 2020-04-01T17:19:52.487995+08:00 VECS0xxxx kernel: [] ? down_read+0x24/0x30 1670 2020-04-01T17:19:52.489596+08:00 VECS0xxxx kernel: [] proc_pid_cmdline_read+0xb8/0x570 1671 2020-04-01T17:19:52.491498+08:00 VECS0xxxx kernel: [] ? mntput_no_expire+0x30/0x110 1672 2020-04-01T17:19:52.495332+08:00 VECS0xxxx kernel: [] ? security_file_permission+0x1c/0x20 1673 2020-04-01T17:19:52.495346+08:00 VECS0xxxx kernel: [] vfs_read+0xb7/0x1a0 1674 2020-04-01T17:19:52.498703+08:00 VECS0xxxx kernel: [] ? fget_light_pos+0x16/0x50 1675 2020-04-01T17:19:52.498717+08:00 VECS0xxxx kernel: [] sys_read+0x51/0xb0 1676 2020-04-01T17:19:52.501884+08:00 VECS0xxxx kernel: [] tracesys+0xb2/0xd8
后续尝试
问题首先发生在主节点,调整min_free_kbytes和zone_reclaim_mode参数后,主节点问题没有再发生。 是否由于把从节点的也调整了,导致了从节点CPU sys飙高挂掉?
1.尝试将min_free_kbytes调低来看下从节点的运行情况,将min_free_kbytes调低到128000
2.从节点也设置了kdump,当节点挂掉后再分析下该文件
原提问者GitHub用户yongliangcode
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
非常详细的描述,看上去调整后只在slave 上面出现了上述状况,原因可能有下面几点:
(1)四个slave 应该是同时部署在了两个ecs上面,所以相对io压力会比主大一些,顺序写也会受影响,从监控上面看,内存也几乎满了。
(2)看了下内核参数的影响,有个地方有些问题:vm.dirty_ratio应该要大于vm.dirty_background_ratio,试下把vm.dirty_ratio改为25,vm.dirty_background_ratio不变。
(3)尝试下升级操作系统,好像是有个操作系统bug也会导致相关的情况,大于2.7的内核对于内存的使用会更加激进一些,当然vm. min_free_kbytes 这些参数也不起作用了。
原回答者GitHub用户duhenglucky
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。
