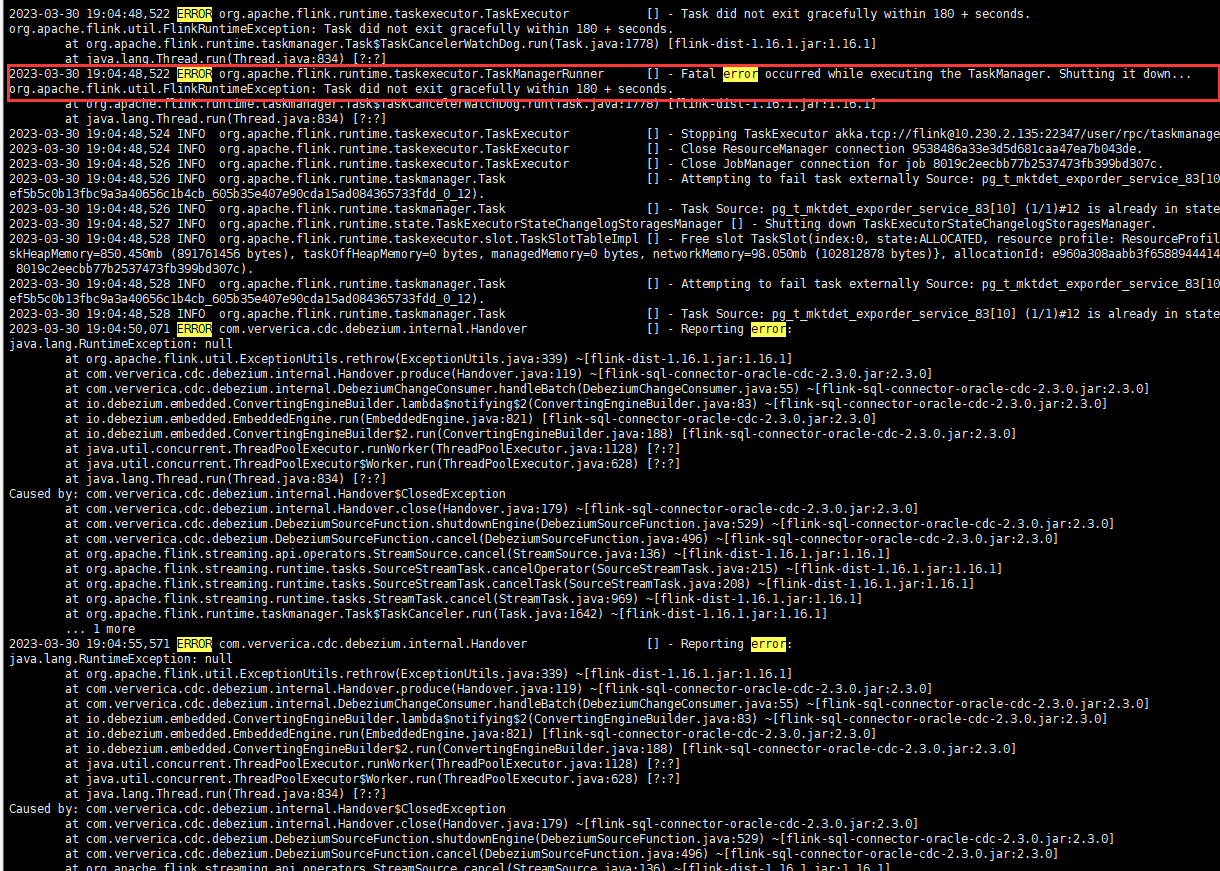
针对您提到的Flink CDC任务失败导致TaskManager停止的问题,可以从以下几个方面进行分析和解决:
-
异常原因分析:
- 资源不足:TaskManager可能因内存溢出(OOM)而异常退出。这通常与数据处理过程中所需的内存超过配置值有关,特别是当数据量大、复杂计算或连接器使用不当导致。
- 连接器问题:如果使用的是特定于CDC的连接器(如Debezium等),确保该连接器与Flink版本兼容,并正确配置了源端和目标端的参数。不正确的配置可能导致数据读取异常或写入问题,进而影响TaskManager稳定性。
- 网络/外部系统问题:外部数据源或目标系统的不稳定、权限配置错误或网络中断也可能导致Task失败。
- Flink配置不当:包括但不限于Checkpoint设置不合理、资源分配不足(CPU、内存)、并行度设置不恰当等,都可能引发任务失败。
-
解决方案建议:
- 检查并调优内存配置:根据作业实际需求调整TaskManager的内存大小,特别是在遇到频繁GC或直接OOM时。考虑增加
taskmanager.memory.process.size配置值。
- 优化连接器配置:确认所有连接器参数正确无误,尤其是对于CDC任务,确保源数据库的变更流能够被正确消费且不会因数据量突增而过载。
- 监控与日志分析:利用Flink提供的日志和监控工具(如JM GC日志),深入分析TaskManager退出的具体原因。
- 资源与并行度调整:合理分配CPU核心数和Task Slot数量,确保资源充分利用且避免过度竞争。同时,根据数据量和处理逻辑调整作业的并行度。
- 检查外部依赖:验证所有外部系统(如数据库、消息队列)的稳定性和配置,确保网络畅通无阻。
- 版本兼容性确认:确认使用的Flink及连接器版本之间不存在已知的兼容性问题,必要时进行升级。
-
注意事项:
- 在进行任何配置更改后,应逐步测试以验证效果,避免直接在生产环境中实施未经验证的改动。
- 定期审查和优化作业配置,以适应数据量和业务需求的变化。
通过上述步骤,您可以系统地诊断并解决Flink CDC任务失败导致TaskManager停止的问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。