
大佬,Flink CDC 这个是需要设置失败次数吗,在哪里,设置同步了5万多条数据,很不稳定,延迟特别严重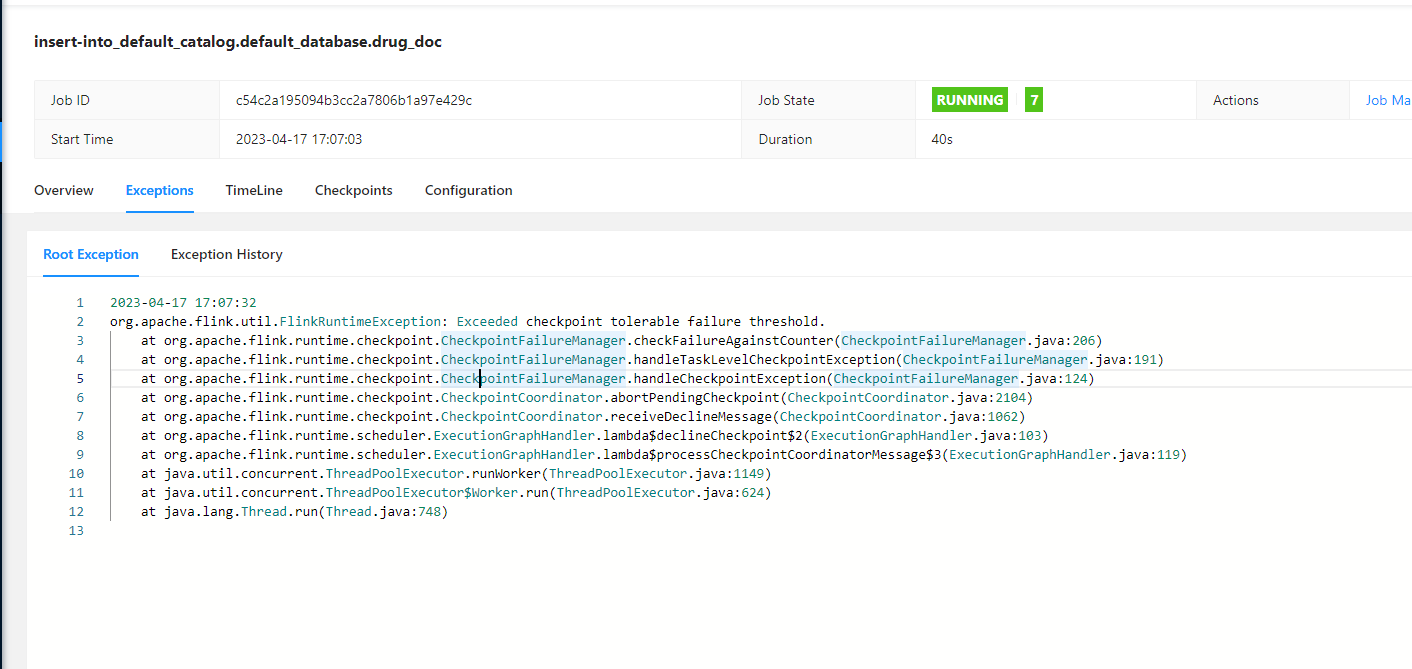
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对您遇到的Flink CDC作业不稳定且延迟严重的问题,可以从以下几个方面进行检查和优化:
配置Checkpoint失败次数: 确保您的Flink作业配置了合理的Checkpoint策略以应对可能的失败情况。可以通过设置execution.checkpointing.tolerable-failed-checkpoints参数来控制Checkpoint失败的最大容忍次数。增加这个值可以给予作业更多机会从Checkpoint失败中恢复,特别是在处理大量数据时。例如,您可以设置一个较大的值如100,这表示系统在放弃之前会尝试恢复100次Checkpoint失败。
调整Checkpoint间隔时间: 通过修改execution.checkpointing.interval参数来设定Checkpoint的时间间隔。如果当前间隔过短,可能导致频繁的Checkpoint操作干扰了正常的任务执行,从而增加了延迟。根据您的数据同步量和稳定性需求,可以适当增加Checkpoint间隔,比如设置为10分钟,以减少对作业的影响。
资源与重启策略优化: 考虑到作业的稳定性,您还可以调整重启策略以避免无休止的重启导致资源浪费或状态混乱。例如,采用固定延迟重启策略并合理设置最大重试次数,如restart-strategy.fixed-delay.attempts: 2147483647,同时指定每次重启之间的延迟时间,确保在资源紧张或故障时有适当的缓冲空间。
监控与调优:
currentEmitEventTimeLag,以判断作业是否已成功完成全量同步并进入增量阶段。数据处理逻辑与外部依赖:
综上所述,为了提高Flink CDC作业的稳定性和降低延迟,您需要综合考虑Checkpoint策略、资源分配、重启策略以及监控调优等多个方面,并根据实际情况做出相应的配置调整。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
