
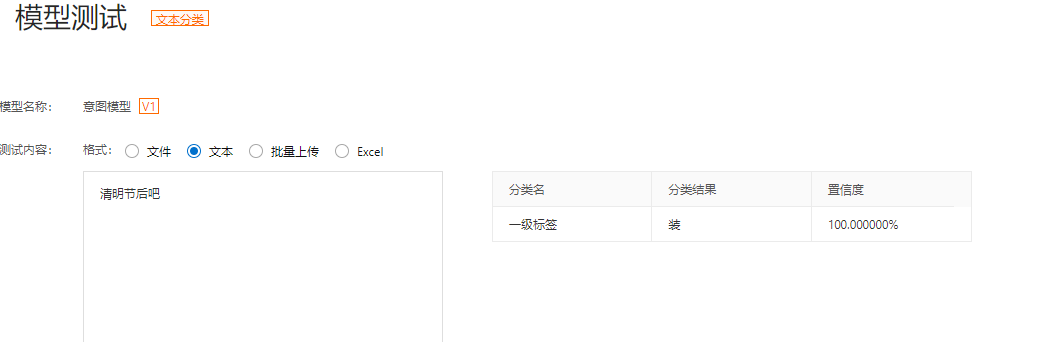
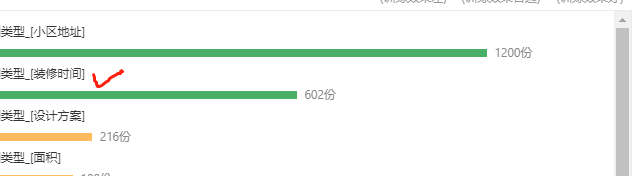
 老师,我问下,我这里标注的分类明明是装修时间,为什么预测的时候,分类结果是“装”?
老师,我问下,我这里标注的分类明明是装修时间,为什么预测的时候,分类结果是“装”?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好!看起来您可能遇到了自然语言处理或文本分类任务中的一些问题。当您的模型预测结果与预期不符时,这可能是由几个因素导致的:
数据标注不一致:首先检查您的训练数据中“装修时间”这一类别的标注是否统一、准确。确保所有属于该类别的样本都被正确且一致地标注。
模型理解能力:模型可能没有充分理解“装修时间”作为一个整体概念。在训练过程中,如果模型遇到的“装修时间”样例不够多或者上下文信息不足以让模型学习到这个类别特征,它可能会错误地将重点放在“装”字上,尤其是如果“装”在其他类别中频繁出现,可能导致模型混淆。
词汇量和泛化能力:模型的词汇量(词汇嵌入)和泛化能力也会影响分类准确性。如果模型对“装修时间”这类专业术语的理解不足,或者训练数据覆盖不够广泛,它可能无法准确区分和预测此类别。
模型超参数设置:模型的超参数(如学习率、批次大小、隐藏层大小等)设置不当也可能影响其性能。有时候过于复杂的模型可能会过拟合训练数据中的噪声,而简单的模型可能无法捕捉到复杂特征。
后处理逻辑:确认一下预测后的处理逻辑是否有误,比如是否有截断或错误解析预测输出的代码。
解决建议: - 重新审查并标准化数据标注,确保每个类别的标签清晰、一致。 - 增加训练数据量,特别是包含“装修时间”类别的样本,以帮助模型更好地学习这一特定分类。 - 优化模型结构或调整超参数,可以尝试使用更复杂的模型结构,或者通过交叉验证来调优超参数。 - 实施数据增强,通过对现有数据进行变换(如同义词替换、句子结构调整等),增加模型的泛化能力。 - 后处理逻辑检查,确保预测结果被正确解释和处理。
如果是在使用阿里云的自然语言处理服务,比如自然语言分类服务,也可以考虑查看官方文档或联系技术支持,了解是否有针对特定问题的解决方案或最佳实践。
