
文档智能这个轮询方法怎么实现呢?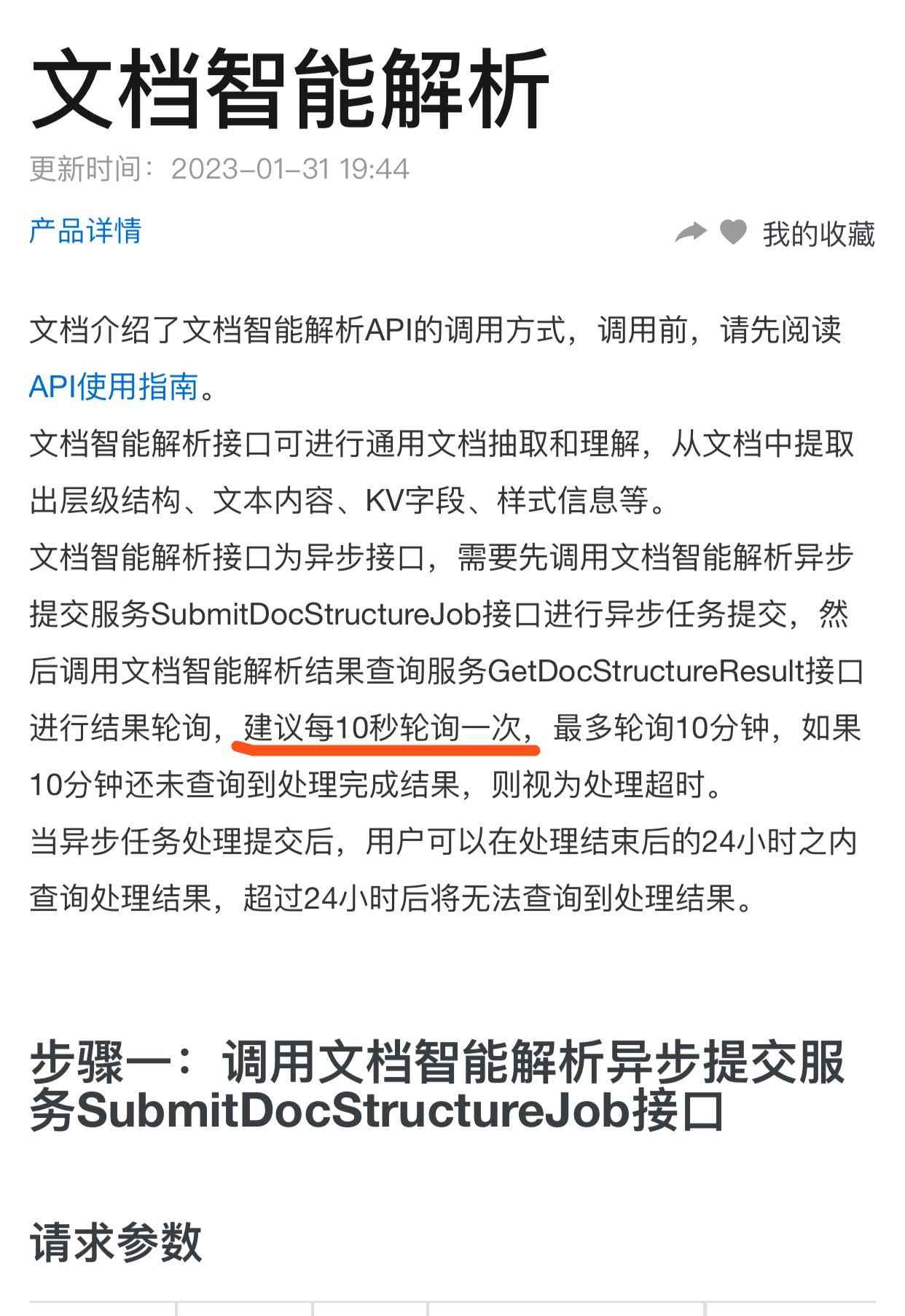
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
定义需求和目标:
确定您希望通过文档智能轮询方法实现什么功能,比如自动分类文档、提取关键信息、监控文档变化等。
数据收集与处理:
收集需要处理的文档数据。
对文档进行预处理,如去除无用的格式信息、OCR识别文本等。
模型选择和训练:
根据需求选取合适的机器学习或NLP模型,如文档分类模型、实体识别模型等。
使用已标注的数据集训练模型。
轮询机制设计:
设计一个轮询系统,这个系统可以定期(比如每隔几分钟)检查文档库中的新文档或文档更新。
配置轮询间隔,以及决定在检测到新文档或更新时要执行的操作。
集成和部署:
将训练好的模型集成到轮询系统中。
将轮询系统部署到服务器或云环境中,确保其可以持续运行。
结果处理与反馈:
设计机制来处理模型的输出,如将提取的信息存储到数据库中。
根据需要反馈结果,比如通过电子邮件通知相关人员。
监控和优化:
监控轮询系统的性能和准确率。
根据反馈和结果持续优化模型和轮询机制。
文档智能识别的轮询方法一般是通过定时任务或者消息队列等方式不断地询问识别任务的状态,一旦任务完成,就可以获取识别结果。具体实现方式可以根据具体的场景和需求进行选择。

