
DMS这边按照文档,加了Spark SQL任务将数据同步到OSS,最终是执行失败了,但是没有任何报错,麻烦帮看下是什么原因? 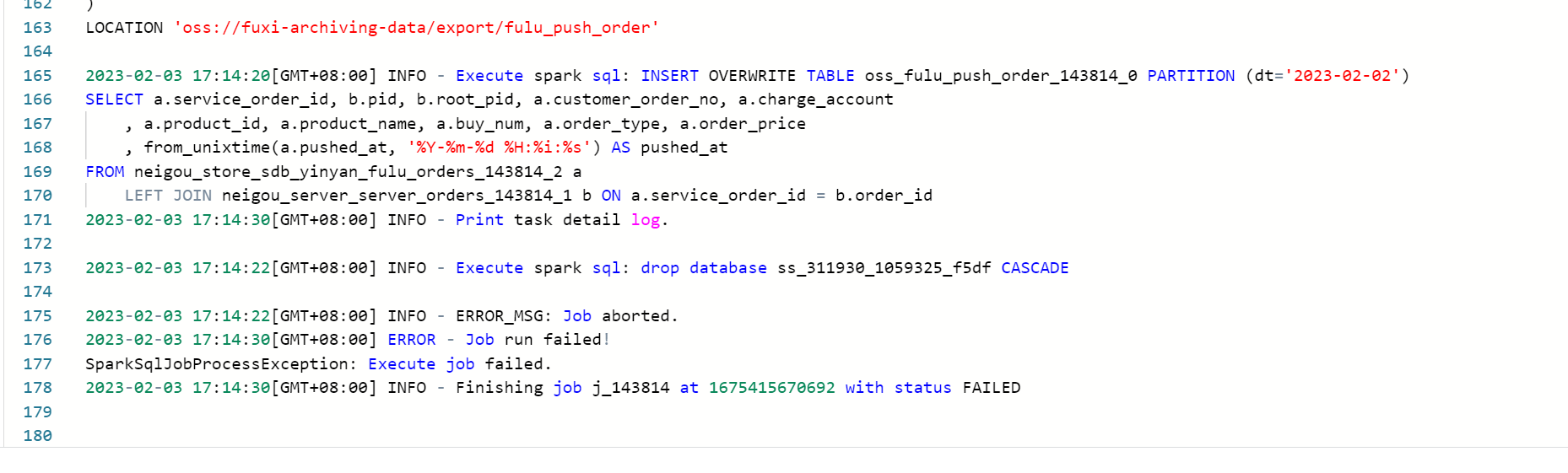 我的sql:CREATE TABLE oss.fulu_push_order ( service_order_id string COMMENT '订单', pid string COMMENT '父订单', root_pid string COMMENT '根订单', customer_order_no string COMMENT '外部订单', charge_account string COMMENT '账户', product_id bigint COMMENT '商品id', product_name string COMMENT '商品名称', buy_num string COMMENT '数量', order_type string COMMENT '类型', order_price float COMMENT '金额', pushed_at string COMMENT '推送时间', dt string comment '业务日期分区' ) partitioned by (dt) COMMENT '订单表';insert overwrite oss.fulu_push_order partition (dt = '${bizdate}')select a.service_order_id, b.pid, b.root_pid, a.customer_order_no, a.charge_account, a.product_id, a.product_name, a.buy_num, a.order_type, a.order_price, from_unixtime(a.pushed_at, '%Y-%m-%d %H:%i:%s') as pushed_atfrom neigou_store.sdb_yinyan_fulu_orders a LEFT JOIN neigou_server.server_orders b on a.service_order_id = b.order_id;
我的sql:CREATE TABLE oss.fulu_push_order ( service_order_id string COMMENT '订单', pid string COMMENT '父订单', root_pid string COMMENT '根订单', customer_order_no string COMMENT '外部订单', charge_account string COMMENT '账户', product_id bigint COMMENT '商品id', product_name string COMMENT '商品名称', buy_num string COMMENT '数量', order_type string COMMENT '类型', order_price float COMMENT '金额', pushed_at string COMMENT '推送时间', dt string comment '业务日期分区' ) partitioned by (dt) COMMENT '订单表';insert overwrite oss.fulu_push_order partition (dt = '${bizdate}')select a.service_order_id, b.pid, b.root_pid, a.customer_order_no, a.charge_account, a.product_id, a.product_name, a.buy_num, a.order_type, a.order_price, from_unixtime(a.pushed_at, '%Y-%m-%d %H:%i:%s') as pushed_atfrom neigou_store.sdb_yinyan_fulu_orders a LEFT JOIN neigou_server.server_orders b on a.service_order_id = b.order_id;
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。


