
dataworks分支节点实现特定时间执行任务分支节点与其它控制节点怎么做?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在数据开发页面,您可以看到当前版本的DataWorks支持的赋值节点、分支节点和归并节点等控制节点。各类型控制节点的作用如下:赋值节点:您可以通过赋值节点把自己的结果传给下游,详情请参见配置赋值节点。 赋值节点复用了配置节点上下文依赖的特性,在已有常量和变量节点上下文的基础上,赋值节点支持自定义的上下文输出。DataWorks会捕获或打印赋值节点的查看结果,并将该结果以outputs形式作为上下文输出参数的值,供下游节点引用。分支节点:可以决定哪些下游正常执行,详情请参见配置分支节点。 分支节点复用了DataWorks上依赖关系设置的输入和输出的特性,详情请参见配置调度依赖。 对于普通节点,节点的输出仅仅是一个全局唯一的字符串。当下游需要设置依赖时,搜索这个全局唯一的字符串作为节点的输入即可挂到下游节点列表中。但是,对于分支节点您可以在设置下游依赖时,选择某一个条件关联的输出作为分支节点的输出。节点在成为分支节点下游的同时,也关联到了分支节点的条件上:满足该条件,该输出对应的下游才会被正常执行。其它未满足条件的输出对应的下游节点,会被置为空跑。归并节点:无论上游是否正常执行,本身都会正常调度。 未被分支节点选中的分支,DataWorks会把该分支链路上所有的节点实例置为空跑实例,即一旦某个实例的上游有一个空跑实例,它本身也会变为空跑。 DataWorks当前可以通过配置归并节点来阻止该空跑的属性无限制地传递下去:无论归并节点实例上游有多少个空跑的实例,归并节点都会直接成功,且不会再把下游置为空跑。下图为存在分支节点的情况下,依赖树的逻辑关系。 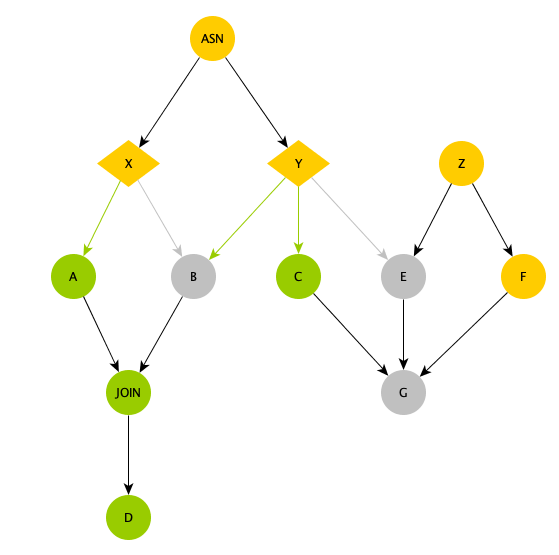 ASN:一个赋值节点,用于对比较复杂的情况进行计算,以便选择分支节点的条件。X和Y:分支节点,处于赋值节点ASN下游,根据赋值节点的输出进行分支的选择。如图中绿色线条所示,X节点选择了左边的分支,Y节点选择了左边两个分支:A和C节点由于在X和Y节点被选择的输出下游,因此正常执行。B节点虽然在Y节点被选择的分支下游,但由于X节点未选择该输出,因此B节点被置为空跑。E节点由于未被Y节点选中,因此即使有一个普通的Z节点上游,也同样被置为了空跑。G节点由于上游E节点空跑,因此 https://help.aliyun.com/document_detail/102756.html——该回答整理自钉群“DataWorks交流群(答疑@机器人)”
ASN:一个赋值节点,用于对比较复杂的情况进行计算,以便选择分支节点的条件。X和Y:分支节点,处于赋值节点ASN下游,根据赋值节点的输出进行分支的选择。如图中绿色线条所示,X节点选择了左边的分支,Y节点选择了左边两个分支:A和C节点由于在X和Y节点被选择的输出下游,因此正常执行。B节点虽然在Y节点被选择的分支下游,但由于X节点未选择该输出,因此B节点被置为空跑。E节点由于未被Y节点选中,因此即使有一个普通的Z节点上游,也同样被置为了空跑。G节点由于上游E节点空跑,因此 https://help.aliyun.com/document_detail/102756.html——该回答整理自钉群“DataWorks交流群(答疑@机器人)”
在数据开发页面,您可以看到当前版本的DataWorks支持的赋值节点、分支节点和归并节点等控制节点。具体怎么做,步骤比较多,详情参见:https://help.aliyun.com/document_detail/102756.html#section-qcb-drs-lgb。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



