
云原生大数据计算服务 MaxCompute中,PyODPS DataFrame是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
为什么需要单独来谈PyODPS DataFrame(以下简写为DF,此处特指PyODPSDataFrame,请注意和Pandas DataFrame区分)?因为在同一段PyODPS代码中,需要特别留意区分普通代码脚本和DF相关脚本。在开发者看来明明是同一套代码,但是其中的DF部分却是在不同的环境里执行的,下面借助这张图进一步阐释。
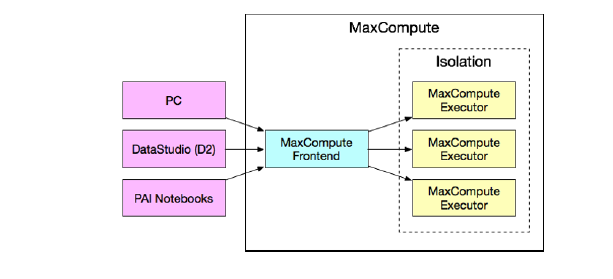
总体上看,可以简单地这么记忆:DF代码会在上图框选的MaxCompute内部执行,非DF代码则会在紫色部分(“本地环境”)执行。
以DataStudio为例,如果是在DataWorks的DataStudio创建了PyODPS2/PyODPS3节点,实际跑这段代码的环境是DataWorks的调度资源组机器(gateway机器),DataWorks已经帮用户配置好了相应的runtime(pyodps依赖、python interpreter等)。因而,这些代码在执行时,行为与普通Python code的执行行为类似,import第三方包时,引用的是“本地”的包,如果您使用的是独享调度资源组,则可通过DataWorks控制台的调度资源组运维助手,进行pip命令的下发来安装必要的三方依赖。
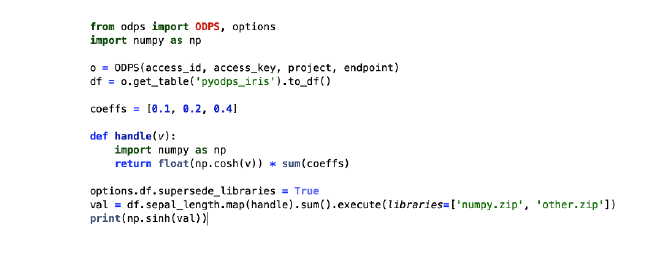
PyODPS DF支持对所有Sequence实现调用map方法,传入自定义函数闭包,实现对于MaxCompute表中某一列的每一个元素逐个调用自定义函数进行处理。如上述代码片段的handle函数。handle函数传入map方法时,会被提取为闭包和字节码,DF使用闭包和字节码生成一个MaxCompute的UDF,在执行时实际等效于:
select this_handle_udf(pyodps_iris.sepal_length)
由此可见,此部分的DF代码执行,发生在了MaxCompute集群内部了,即上图中的MaxCompute Executor机器上执行。
进一步来说说如果在自定义函数里使用到了三方包,因为自定义函数在Max-Compute Executor机器上执行,所以无法引用“本地环境”的包,import建议放在自定义函数内部进行,并且在DataWorks上上传三方包资源后,需要点击“提交”确保资源被正确上传到MaxCompute集群内部。
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。



