
请问如果我同步的hive表是分区表,分区字段是insert date,在配置离线同步界面应该怎么弄呀?这样好像不太对 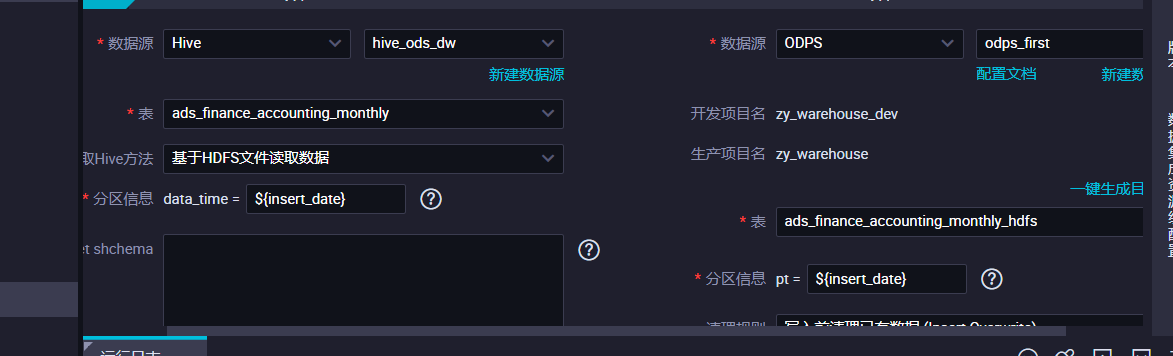
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在配置离线同步任务之前,首先需要确认待同步数据源支持的数据源与读写能力,MaxCompute支持离线同步的单表读、单表写  而整库离线同步方案包括周期性全量同步、周期性增量同步、一次性全量同步、一次性增量同步、一次性全量周期性增量同步。这里根据操作步骤如何将整库数据离线同步至MaxCompute,具体步骤参考https://help.aliyun.com/document_detail/302449.html,由于你操作不熟练,建议参考官方文档逐步操作,加深记忆,防止出错,文档中明确了每一步的任务,逐步执行即可
而整库离线同步方案包括周期性全量同步、周期性增量同步、一次性全量同步、一次性增量同步、一次性全量周期性增量同步。这里根据操作步骤如何将整库数据离线同步至MaxCompute,具体步骤参考https://help.aliyun.com/document_detail/302449.html,由于你操作不熟练,建议参考官方文档逐步操作,加深记忆,防止出错,文档中明确了每一步的任务,逐步执行即可
1、在DataWorks的数据开发页面,新建一个业务流程。 2、新建一个离线同步任务。 - 展开新建的业务流程,右键单击数据集成,选择新建 > 离线同步。 - 在新建节点对话框中,输入节点名称,单击提交。 3、在选择数据源区域中,将数据来源指定为HIVE数据源,并填入待同步的表名称;将数据去向指定为ODPS数据源,并填入索引名和索引类型。
同步的hive表是分区表,分区字段是insert date,在配置离线同步界面,这个楼主可以直接去阿里云对应的文档中查看啊,文档里面写的很清楚,这里就不贴具体链接了。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



