
并行计划生成的过程是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如下图所示, 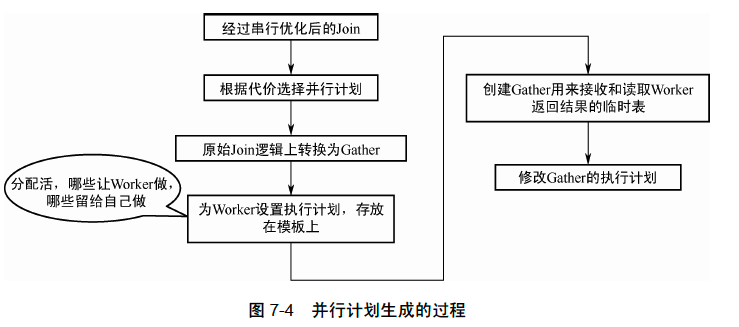
经过串行执行优化后,PolarDB 的优化器会根据当前的代价判断是否需要并行执行:检查串行代价是否大于并行查询的阈值,表是否支持并行扫描,扫描行数是否大于设定的阈值,计算并行查询的代价,并进行比较。
只有优化器认为并行执行更优时,才会生成并行计划。PolarDB的并行执行框架只有1 个Leader/Gather 线程,因此当生成并行计划时,目标是将尽可能多的算子和表达式计算下推到Worker 线程并行执行。这样做,一方面减少数据传输代价,另一方面可让更多的计算并行执行。
以上内容摘自《云原生数据库原理与实践》,这本书可以在电子工业出版社天猫店购买。


