
Aurora 写的流程是怎么样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
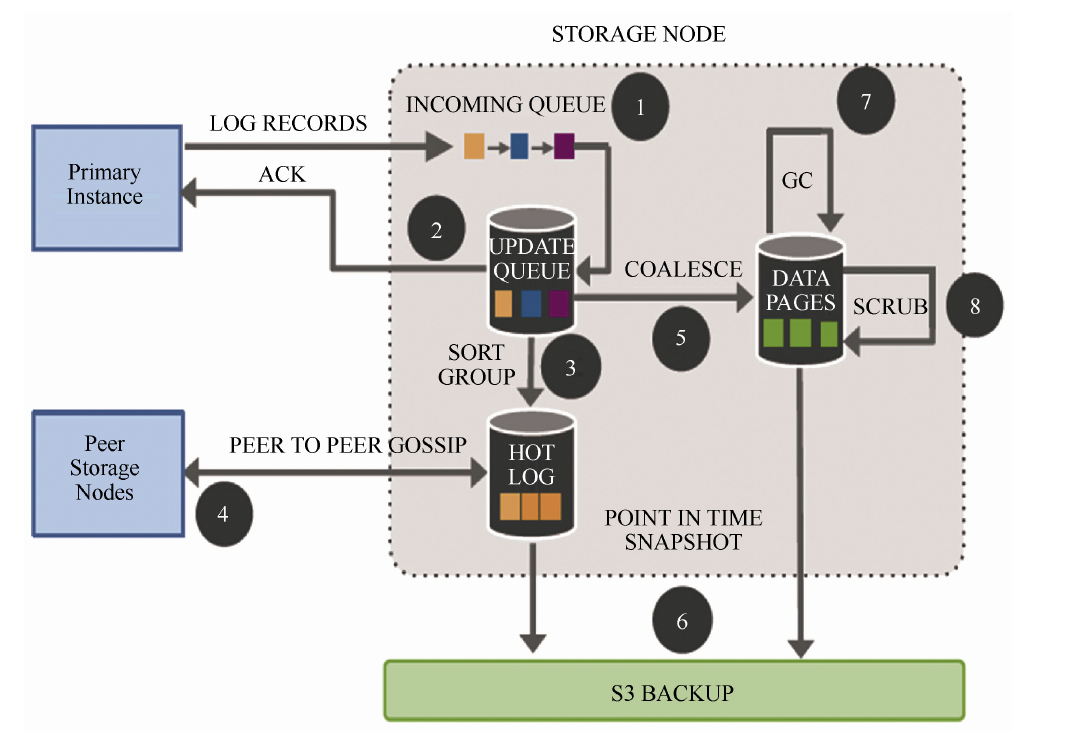
如图所示,Aurora 写的流程是:
①存储节点接收数据库实例的日志,并追加到内存队列;
②将日志在本地持久化成功后,给实例应答;
③按分片归类日志,并确认丢失了哪些日志;
④与其他存储节点交互,填充丢失的日志; ⑤回放日志生成新的数据页;
⑥周期性地备份数据页和日志到S3 系统; ⑦周期性地回收过期的数据页版本;
⑧周期性地对数据页进行CRC 校验。
上述所有写相关的操作,只有第①和第②步是串行同步的,会直接影响前台请求的响应时间,其他操作都是异步的。
以上内容摘自《云原生数据库原理与实践》,这本书可以在电子工业出版社天猫店购买。


