
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
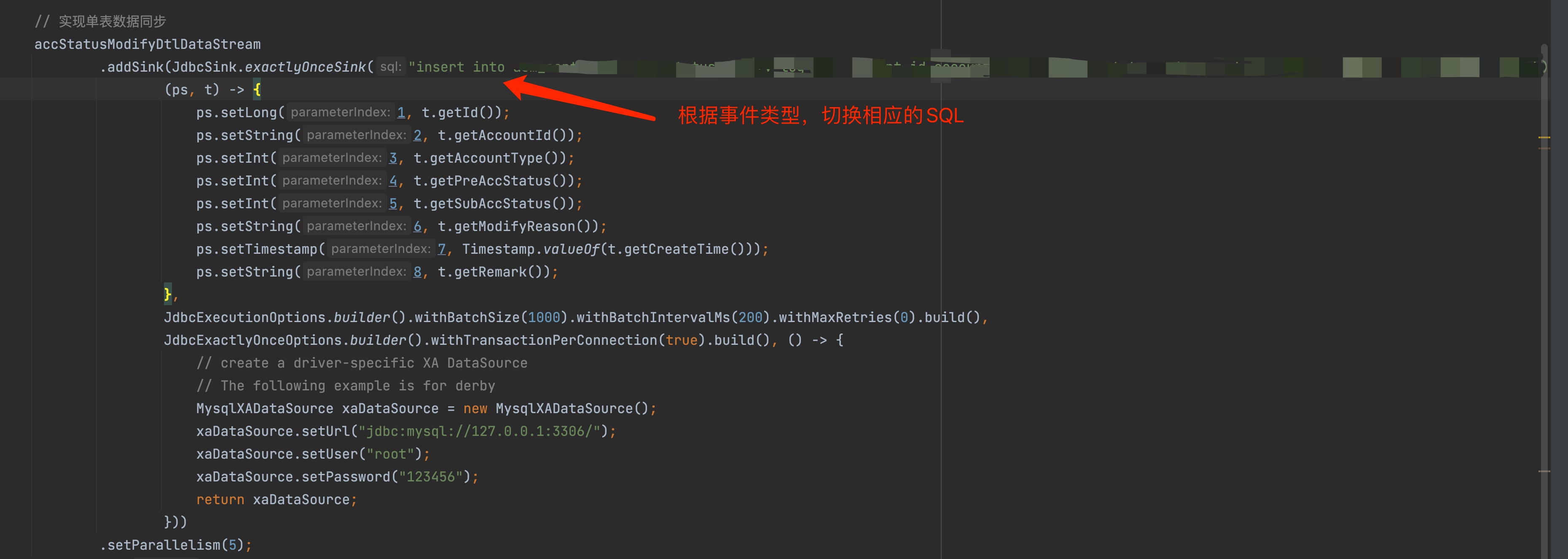
Flink Connector JDBC 本身不支持根据事件类型选择不同的自定义 SQL。但是,您可以通过编写一个自定义的转换器来实现这个功能。
具体来说,您可以编写一个转换器,该转换器将事件数据转换为多个表,每个表对应于不同的事件类型。然后,您可以使用 Flink JDBC 连接到这些表,并使用不同的 SQL 查询它们。
以下是一个简单的示例代码:
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
public class JdbcCustomSqlSink extends RichSinkFunction<Row> {
private StreamTableEnvironment tableEnv;
private String eventTypeColumnName;
private String sqlForEventTypeA;
private String sqlForEventTypeB;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
tableEnv = StreamTableEnvironment.create(getContext().getExecutionEnvironment());
eventTypeColumnName = "event_type";
sqlForEventTypeA = "SELECT * FROM table_a WHERE event_type='A'";
sqlForEventTypeB = "SELECT * FROM table_b WHERE event_type='B'";
}
@Override
public void invoke(Row value, Context context) throws Exception {
String eventType = (String) value.getField(eventTypeColumnName);
if (eventType == null || eventType.isEmpty()) {
throw new IllegalArgumentException("Missing event type column");
} else if (eventType.equals("A")) {
tableEnv.executeSql(sqlForEventTypeA, Collections.singletonList(value), new Collector<Row>());
} else if (eventType.equals("B")) {
tableEnv.executeSql(sqlForEventTypeB, Collections.singletonList(value), new Collector<Row>());
} else {
throw new IllegalArgumentException("Unknown event type: " + eventType);
}
}
}
在这个示例中,我们创建了一个名为 JdbcCustomSqlSink 的类,它继承了 RichSinkFunction。在 open() 方法中,我们初始化了 StreamTableEnvironment 并设置了事件类型列名、SQL语句等参数。在 invoke() 方法中,我们根据事件类型选择不同的 SQL 语句进行处理。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



