
请问pyodps的dataframe.persist 方法的running_cluster 是怎么设置的,cluster是否需要创建?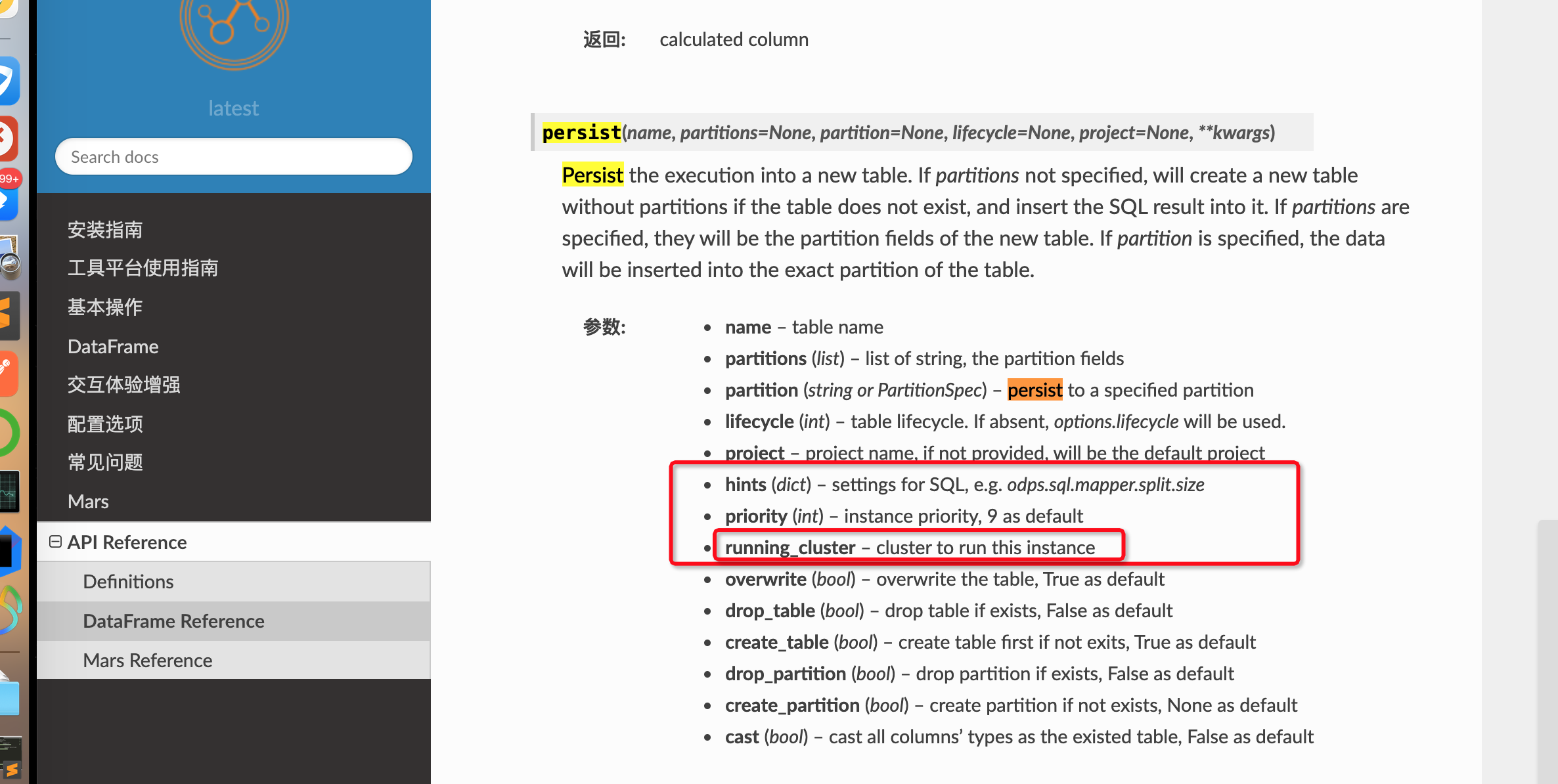
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在PyODPS中,DataFrame.persist方法用于将DataFrame的结果数据持久化到MaxCompute表中,这有助于加速后续对相同数据集的操作。关于您提到的running_cluster设置问题,实际上DataFrame.persist方法并不直接接受一个名为running_cluster的参数来指定执行任务的集群。但是,您可以间接控制任务的执行环境通过配置ODPS对象的执行选项或者在persist操作时通过hints参数来指定。
全局配置ODPS对象: 在初始化ODPS对象时,可以通过指定project和endpoint间接影响任务的执行环境。不同的项目和Endpoint可能关联到不同的计算资源或集群。例如:
o = ODPS(
access_id,
access_key,
project='your_project', # 指定项目名称
endpoint='your_endpoint' # 指定Endpoint
)
使用hints参数自定义执行配置: 在调用persist方法时,可以传入hints参数来指定一些执行时的高级选项,比如可以尝试通过odps.sql.execute.pool来指定执行使用的pool,进而间接影响到集群选择。但请注意,具体可配置的hint选项及其效果依赖于MaxCompute服务的实际支持情况。
df.persist('your_table_name', hints={'odps.sql.execute.pool': 'your_desired_pool'})
综上所述,虽然不能直接为DataFrame.persist指定运行集群,但通过合理配置ODPS对象和利用hints参数,可以在一定程度上影响任务的执行环境。而实际的计算资源(集群)是由MaxCompute服务根据项目与Endpoint的配置动态分配的,无需用户手动创建集群。
