
shake数据库中redis-shake 同步时OOM ,是什么原因啊? 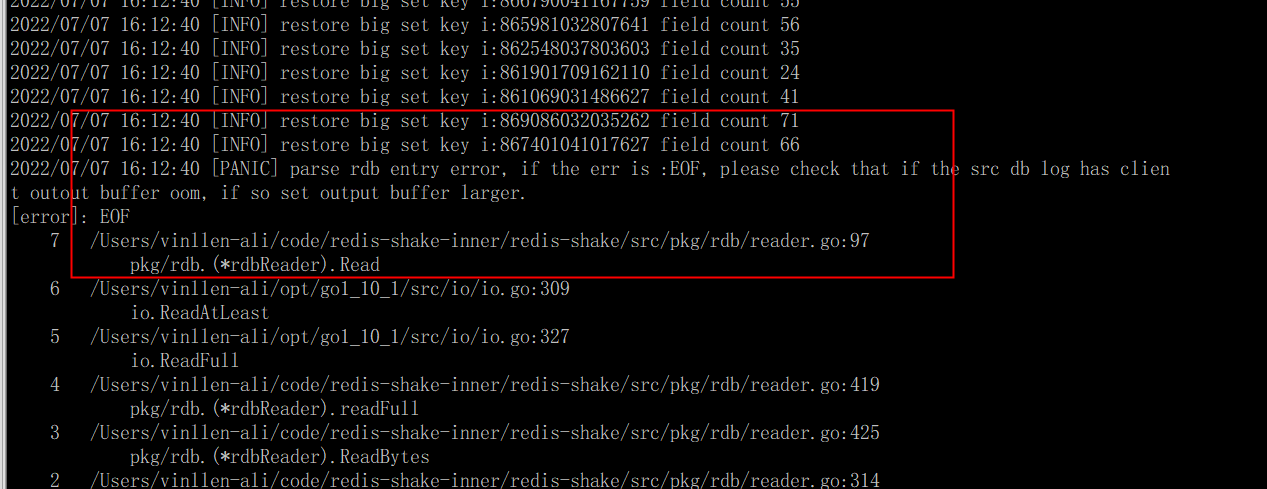
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
问题分析: 当Redis-Shake在同步数据时遇到OOM(Out Of Memory)问题,这通常与以下因素有关:
内存分配超限:Redis-Shake运行过程中,如果单个节点的计算内存使用量超过了配置的上限(如超过20 GB),就会触发OOM。这可能是由于同步的数据量大、查询复杂度高或数据结构设计不合理导致的内存消耗激增。
数据处理策略:不同于某些系统采用磁盘缓存作为算力不足时的降级方案,Redis-Shake为了保证效率,默认所有操作都在内存中进行,没有Spill to Disk机制,因此对内存资源的需求更为直接和严格。
可能原因及排查步骤:
查询优化:检查是否有复杂的Query或大量数据扫描操作导致单个Query内存使用过高。可以通过优化SQL逻辑、增加过滤条件、避免使用如UNION ALL等可能导致内存压力增大的操作来减少内存占用。
资源组配置:确认Redis-Shake运行的资源组配额是否过低(如小于30%)。资源分配不足会直接限制可用内存,从而引发OOM。需要重新评估并调整资源组的资源配置。
数据倾斜与Shard Pruning:数据分布不均或Sharding策略不当也可能导致特定节点内存水位升高至OOM。通过检查执行计划和数据分布情况,识别并解决数据倾斜问题,合理设计Distribution Key以平衡负载。
大基数多阶段GROUP BY:对于聚合操作,特别是涉及大基数分组且分组键与数据分布不匹配的情况,可能会因HashTable过大而耗尽内存。考虑调整相关参数,如设置hg_experimental_partial_agg_hash_table_size来限制Aggregation阶段的内存使用。
解决方案建议:
性能调优:根据上述分析,首先尝试优化数据处理逻辑,简化或拆分复杂查询,确保查询高效且内存友好。
资源调整:检查并适当增加Redis-Shake运行实例的内存配额,同时确保资源组配置合理,避免因资源限制引发的内存溢出。
架构优化:针对数据倾斜问题,实施数据重分布或调整Sharding策略,确保数据均衡存储。
参数优化:对于特定场景下的内存密集型操作,通过调整相关参数限制内存使用峰值,以预防OOM。
特别提醒:
综上所述,Redis-Shake同步时出现OOM,需从查询优化、资源管理、数据分布以及参数配置等多个维度综合分析并采取措施。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。

