
如题
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
【调度依赖关系设置】 DataWorks通过节点输出挂依赖,上游节点的输出作为下游节点的输入形成依赖关系。如下图: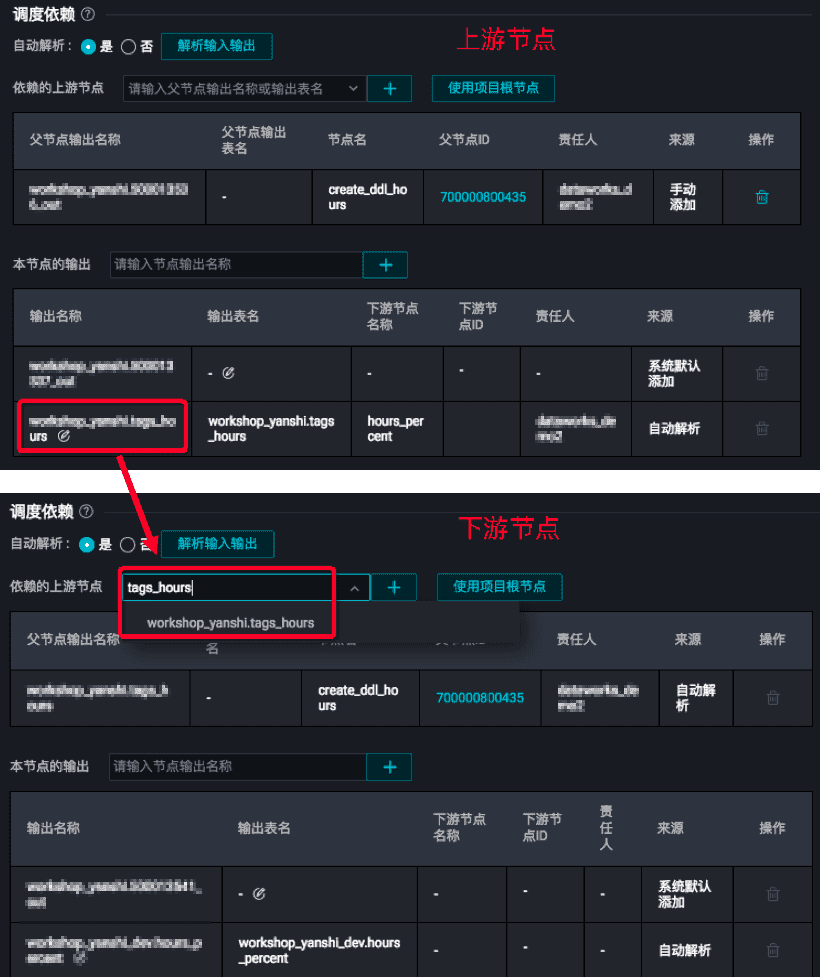 【自动解析】--建议使用☆ select 一张表会将自动解析作为本节点依赖的上游。 insert / create一张表,该表会自动解析作为本节点的输出。
【自动解析】--建议使用☆ select 一张表会将自动解析作为本节点依赖的上游。 insert / create一张表,该表会自动解析作为本节点的输出。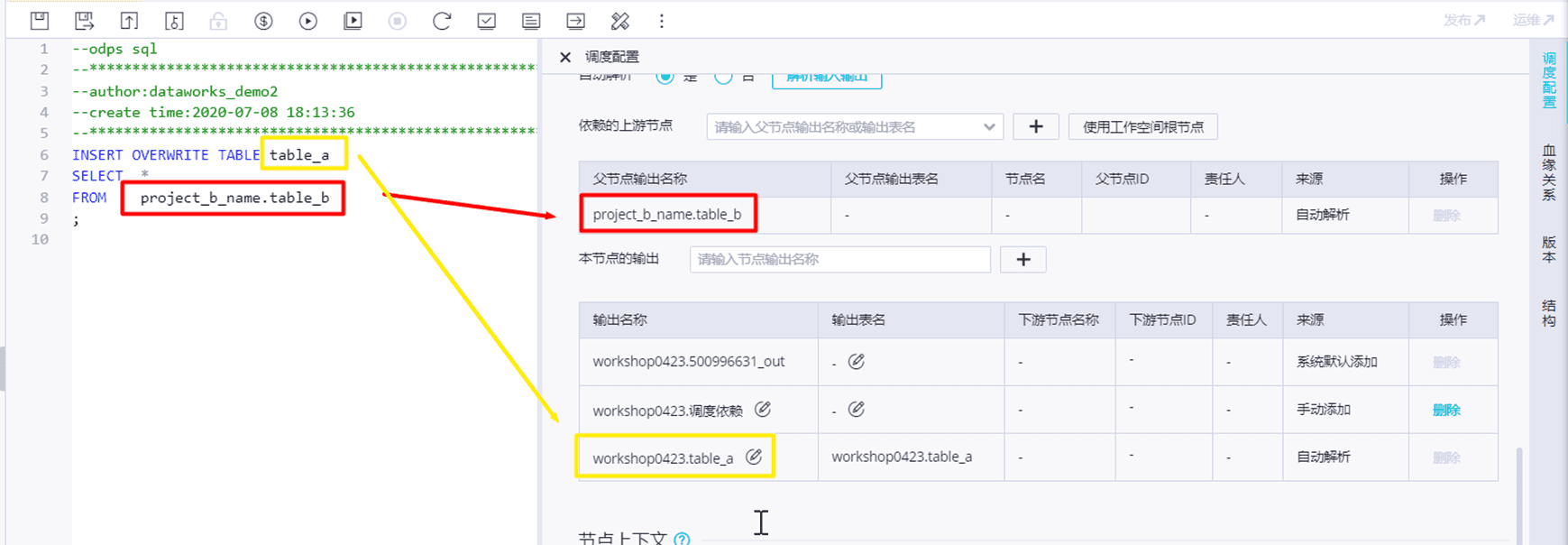 【自定义依赖】--不建议使用
【自定义依赖】--不建议使用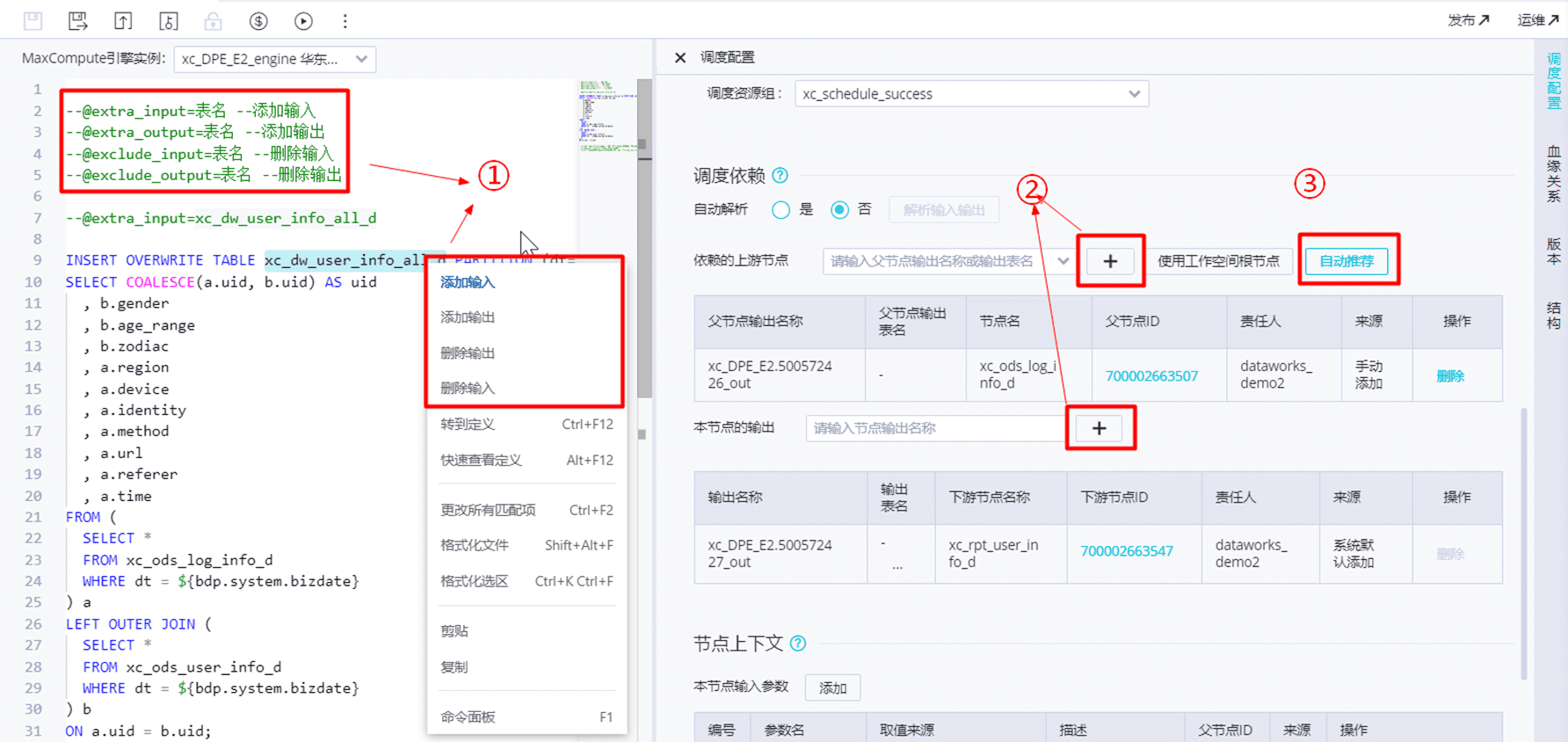 删除输入输出
删除输入输出
本地上传的表数据,非每天调度更新的数据,任何时候取数据都没有问题,不需要设置调度依赖,可以删除输入。
手动添加上游输出
自动推荐
自动推荐功能会自动解析出所有已经提交并发布至生产环境,并且实际运行产出该表的节点。自动解析设置为否时可用。
拉线设置依赖关系
默认会将上游节点的out输出作为下游节点的输入,符合DataWorks依赖关系设置。(此答案整理自DataWorks交流群(答疑@机器人))
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

