Hudi 存储模式和视图是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
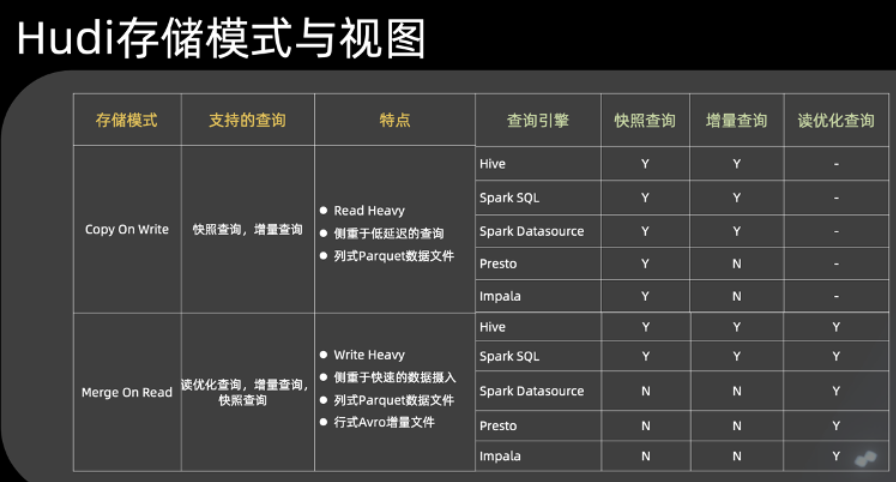
第一个是 Copy On Write 模式,对应到 Hudi 的 COW 表。它是一种侧重低延时的数据查询场景的表,底层使用 Parquet 数据文件存储数据,能够支持快照查询和增量查询两种查询方式。在查询引擎方面,大家可以看到上面有 5 个引擎,他们对快照查询、增量查询和读优化 3 种视图都有不同程度的支持。
Merge On Read 表对 Copy On Write 有不同层面的互补,可以看到它侧重于快速的数据摄入场景。使用 Parquet 文件来存储具体的数据,使用行式 Avro 增量文件来存储操作日志,类似于 HBase WAL。它支持 Hudi 所有 3 种视图,可以看到 Hive,Spark SQL,Spark Datasource, Presto 和 Impala 对于读优化查询都是支持的。而 Hive, Spark SQL 只支持到了快照查询。